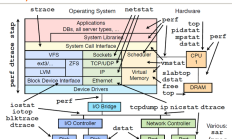
性能分析工具 先看一张图: 上图是 Brendan Gregg 分享的性能分析,这里的所有工具都可以通过人工获取其帮助文档。这里简单介绍一下它的常规用法: vmstat - 虚拟内存统计 vmstat(VirtualMeomoryS...
前提条件服务器已安装宝塔面板。如果没有,可以使用以下命令一键安装yum install -y wget && wget -O install.sh https://download.bt.cn/install/install...
字数超出限制了...
Linux系统好用吗?常规服务器系统一般选择Windows和Linux系统。如果前者不需要用于远程桌面目的或者如果有带有ASP和ASP.NET服务的网站程序。一般来说,会使用Linux系统的优先于后者。它有丰富的免费软件包和多个发行版本可供...
什么是rsync? Rsync 是一款快速灵活的文件复制工具。它可以通过远程 shell 或远程 rsync 守护进程在本地复制到另一台主机。它提供了许多选项来控制其行为的各个方面,并允许非常灵活的文件规范进行复制。它以其增量传输算法而闻名...
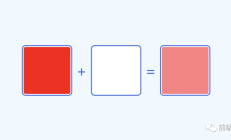
CSS实现圆角边框渐变色+背景透明。最近工作中经常能达到这些效果,快来get吧~1。实现效果2。实现原理 border-image: border-image CSS 功能可以在元素的边缘绘制图像。这使得绘制复杂的布局组件变得更加容易,并且...
用于对齐文本和字符之间空格的 CSS 处理技术。在这里你可以了解文本过渡、字母间距、文本对齐、最后文本对齐、过滤等等,get it ~1。实现效果此处插入图片描述2.实现原理在开始文章之前,我们先来了解一下实现原理2.1 文本渐变颜色实现...
锚点定位❝CSS 锚点定位是一项实验性的新 CSS 功能,允许您相对于页面上的另一个元素定位一个元素。这是使用属性 锚点位置 完成的。例如,以下代码将元素定位到锚元素左侧 10px 处: ❞.element { anchor-posit...
介绍 Chrome 111+ 正式推出的 CSS 混色函数: color-mix()❝♷[1] 。 所谓混色,顾名思义,就是两种颜色按照特定的比例混合,这更像是一个调色板。可以说是迄今为止最强大、最实用的CSS颜色处理功能。这样就无需使用...
 code前端网
code前端网