公司开始了新的网站项目。我已经把生成sitemap.xml文件的工作交给了负责该项目的负责人,但他从未做过。 ,于是就去百度查找别人的经验。 我尝试过很多百度上其他人分享的解决方案例如使用在线站点地图生成工具,手动构建站点地图,收集站点范围...
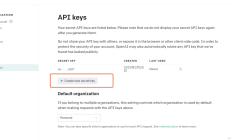
1个接口调用我们可以使用OpenAI的API接口来实现很多NLP任务,还可以支持生成图像、提取embeddings和refine等功能。接下来我们看看如何调用该接口。 生成密钥首先我们需要从URL生成我们的API密钥:,:获得密钥后,我们就...
字数超出限制了...
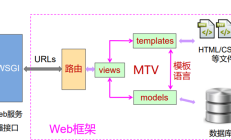
1. Django 概述Django 是一个用 Python 编写的开源 Web 应用程序框架。采用MTV的框架模式,即模型M、视图V和模板T。 Django框架的核心组件是: 用于创建模型的对象关系映射; 为最终用户设计更好的管理界面;...
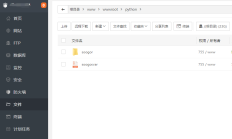
宝塔界面的正常安装是通过Python项目管理器进行的。 第一步:上传文件将soogorCMS下的soogor文件夹上传到服务器。如果文件太多,可以打包上传,然后解压。 同时我们选择以下权限,给用户组www添加写权限第二步:打开端口宝塔接口...
Django mptt 是 Django 的第三方组件。目标是使 Django 项目能够在数据库中存储分层数据(树数据)。主要实现了改进的前序遍历算法。如果你不太了解原理的话可以看我的这篇文章。当然,在使用mptt时,你不需要了解原理,因为...
session的作用和cookie类似,都是存储与用户相关的信息。不同的是cookie存储在本地浏览器中,而session是存储授权信息的一种思想、概念和服务器解决方案。不同的服务器、不同的系统、不同的语言有不同的实现。尽管应用程序不同,但...
djangoForeignKey是Django数据库设计中经常使用的字段函数。无论是在 models.Model 还是 Forms.model 中,您都需要知道如何使用它。从细节上真正理解djangoForeignKey(外键)的具体功能,...
如果您更换Django开发环境或者开发完成后需要将项目转移到生产服务器,则必须使用与开发环境。我们需要在服务器上搭建工作环境和开发环境一样。 Django 不需要我们以同样的方式安装它。使用 fatrequirements.txt 是一个很...
问题描述WARNING: Ignoring invalid distribution -ip (d:\xxxxxxxx\venv\lib\site-packages) WARNING: Ignoring invalid distributi...
 code前端网
code前端网