PostgreSQL 16现已推出,该版本包含许多新功能和改进;包括: 启用 FULL 和 RIGHT INNER OUTER 哈希联接 的同步 启用备用服务器的逻辑复制 启用订阅的逻辑复制 I 统计监控/允许对新 I/Osstiq...
1。不要使用 mysql_ 函数“不应该”使用 mysql_ 函数的这一天终于到来了。 PHP 7 已将它们从核心中全部删除,这意味着您必须转向更好的 mysqli_ 函数或更灵活的 PDO 实现。 2。不要编写垃圾代码这可能很容易理解,但...
可以说2017年是Web应用和API年。开发人员不必每次都重新发明轮子。相反,他们可以使用第三方脚手架和库来确保项目可以在几天内实时部署。 虽然 RESTful API 和跨平台库使 Web 开发变得更加容易,但它们仍然没有解决阻碍和分隔...
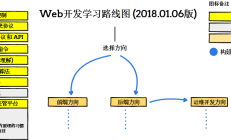
路线图主要展示成为前端开发人员、后端开发人员或运维协调员的技术学习路径。 终极学习指南最重要的是掌握HTML、CSS和JavaScript。系统太多,不需要了解太多。学一两件事就行了,多关注一下Vue。 后端学习曲线后端技术仍然倾向于P...
我们来看看5个维度。不过在我们说话之前,我先写了一个程序,其中包含了指针的“两个自体和三个其他”维度,然后一一解释了每个维度的含义。看看是否会出现这种情况。 在大多数使用指针的场景中,这5个维度应该足以帮助你理解。但是,在一些使用指针的特殊...
1.问题描述 在继承体系中,如果派生类想要使用基类的构造函数,必须在构造函数中显式声明。 例如:struct A { A(int i){} }; struct B:A { B(int i):A(i){} };这里B是从A派生出来的,B...
如果在帝国官方组合中的URL上点击相同字段不同值两次以上,就会出现重复参数。当然不影响功能,而且感觉不美观! 优化前: /e/action/ListInfo .php?&classid=19&orderby=psalenu...
程序员为虾米音乐“可怜新浪科技报”道歉 11月20日下午消息,昨晚某技术论坛发表文章,讨论阿里巴巴虾米音乐客户端Mac版有关VIP会员码的评论。所谓的“可怜的VIP”出现在上面的照片中。 (活动时送的那种)”。今天,虾米音乐App前员工巴佐...
程序员一生与虫子作战,杀敌无数。难怪他这么奇怪!某知识社会平台上,出现了一个话题《有哪些bug让程序员晕倒?》吸引了超过 6700 万次观看。可见程序员对这个问题有多敏感?在这篇文章中,笔者特意挑选了一些优质答案,供程序员参考! 1。 MI...
24。十月是编程界的一个大节日。这一天被称为程序员日。 程序员在今天变得越来越重要,因为互联互通已成为所有企业的战略,并且技术正在被用来改变未来。企业必须对现在和未来承担社会责任,程序员有责任引领万物互联的未来。该公司是否真正重视技术,从其...
 code前端网
code前端网