 code前端网
code前端网接近大模型:ChatGPT 如何构建和清理数据?
数据是基础,这是当前LLM实践者的共识,尤其是高质量的数据。根据ChatGPT不同阶段的训练过程,数据也分为预训练数据(GPT)和细化微调数据(SFT、RLHF)。第一种方法使用自回归方法对尽可能多的数据独立执行上下文化。学习基本的大语言模型,后者使用多样化且高质量的指令样本(三元组)来激发大语言模型的能力并对齐下游任务或用户输入。两个阶段的目标不同,相关的数据需求、数据采集和清洗等也不同。
1。预训练数据
主要由数据获取、数据清洗、数据匹配三部分组成。
1。数据获取
通常分为来源、自建和爬取三种。常见的开源类型包括维基百科、书籍、CommonCrawl、代码、聊天等。下图列出了LLama使用的数据分布。 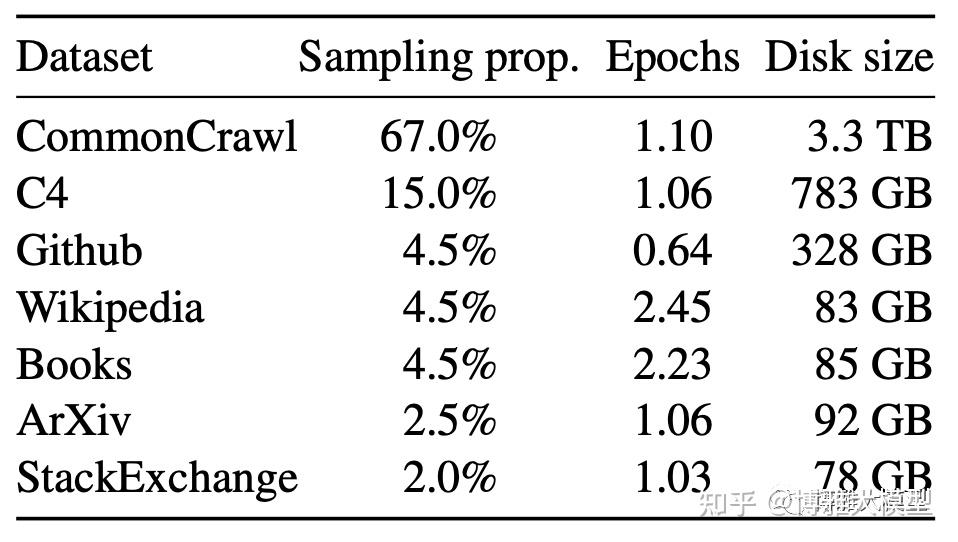
其中,基本上每个LLM都开始使用维基百科,因为它的质量较高。书籍为更长时间的情境学习提供了语料库。如今,每家公司都专注于按主题对书籍进行数字化和提取。代码数据可以强化模型的逻辑推理,因为它的实现通常是分步且合乎逻辑的。 组织自己的数据并尽可能爬取外部数据是LLM项目讨论中最常见的话题。 在中文领域,常见的数据可以分为几个级别,A级:知乎、小红书、顶级GZH/头条文章、百科、经验、专业新闻网站、政务网站、行业垂直网站如起点、锦江之星、电子传统书籍;文件B:英文数据集被翻译成中文,主要是因为英文原文的质量很高。实践中出现严重的翻译问题(句子不流利、专业单位和英语需要翻译等); C文件:知道、今日头条、抖音快手、自媒体新闻、微博、社区等UGC数据。这里的手稿清理存在很多问题,有价值的数据需要清理掉。 它还处理视频的字幕和语音数据的筛选,尤其是与电影和电视节目相关的视频。
以上是比较通用的数据收集方法。结合任务树以便有针对性地补充相关数据也非常关键。任务树是指模型期望具有相应能力的任务。这些任务可以概括为树状层次结构。在数据收集的冷启动阶段之后,根据可用样本训练模型的一个版本。根据模型对不同任务的评估结果,对表现不佳的任务补充相应的样本。以后还会用到这个方法。示例说明也适用。不足的地方就弥补,难以改变的地方就弥补。
2。数据清洗
可以分为通用清洗方法和针对具体情况的清洗方法。一般清洁分为三个维度:质量、重复和安全。其中,质量更容易理解。主要去除一些低质量的文本,比如句子乱序、含有奇怪的字符等。它可能会使用一些统计规则或针对某些特定的统计规则。这些维度用于以传统方式构建监督分类模型。重复数据删除分为三个细化:句子内、文档内和语料库内。目标是清理不合理的重复,因为互联网文本有非常严重的清理和处理问题,以避免解码时重复输出。 也有作品认为大模型对重复非常敏感,应该尽可能多地进行去重。复制是重中之重。 人们的学习方式,很多知识只学一次,只有困难的知识才需要多次学习。在学习大量样本时,过多的重复样本会影响大型模型的性能。安全是指从主题中删除敏感内容、不健康内容等。它也被称为 NSFW 过滤器(非世界安全)。
第二种清洁方法是根据情况进行的。根据不好的评估案例或者上级报告的不好的案例,结合训练数据检索调试系统,可以判断训练样本中是否存在相似的模式,以及这些样本是否也存在相似的问题。 Badcase 通常可以代表某种类型的问题或流程错误。通过从该案例中得出结论并查找类似案例,您可以清理与特定类型问题匹配的数据。这就是彻底、高效的数据评估至关重要的地方。 相对来说,大模型前期优先选择一些通用的清理,而中后期则以案例为主的清理更为关键。
3。数据关系
预训练过程比较耗费资源,而且训练过程往往是不可逆的。实验成本比较高,想要算比较完整的消融实验就更不可能了。同时,光是数据维度就存在很多变量,尤其是数据匹配,包括中英文匹配、不同来源的数据匹配、不同任务的数据匹配、不同质量的数据匹配(过滤掉低质量数据可以还是有比较多的好样本,过滤错误)。这里常见的方法是用小LLM进行实验,得到合适的比例,然后将结论传达给大LLM。
2。细化微调数据
与上面的预训练阶段相比,指令微调阶段更注重样本质量和种类,两者缺一不可。 缺乏多样性导致预训练模型有这个能力,但微调模型没有。 质量保证也是每个人都非常投入的工作,甚至通过了所有的人工检查。内部自研更多的是收集开源指令数据、翻译英文指令数据、爬取ChatGPT以及对常见下游任务数据集进行采样以转换为指令式添加以实现快速冷启动。其次,任务树和案例驱动程序相结合,手动标记主动学习中的示例。在贴标过程中,样品选择、贴标标准、验收等比传统操作更为复杂,需要反复考虑。
一些工作发现,使用少量指令样本进行调优可以快速提高某些任务的模型性能。事实上,仅仅坐下来依赖少量的示例说明是完全不可能的。如果您尝试构建通用的大型模型,则预训练和微调至关重要。预训练可能更重要,因为据说指定微调的作用只是为了激发大模型的能力,而大模型本身的能力在预训练阶段就已经存在了。
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。





