 code前端网
code前端网ChatGPT 原理,国外大神保姆级解说!
作者|乔恩·斯托克斯译者|弯月编辑|郑丽媛出品|CSDN(ID:CSDNnews)
最近很多很聪明的PT人在争论,但我感觉NPT是否已经讨论过,但都没有说到重点。他们对机器人的核心部件以及部件如何协同工作没有透彻的了解。
需要明确的是,我并不声称了解有关 ChatGPT 的一切。我和其他人一样,包括活跃的机器学习研究人员,仍在学习和思考。
希望通过这篇文章阐述我的理解,帮助其他“留守”人士。 ![]()
![]()
机器学习:基础知识
ChatGPT 的核心是来自生成机器学习模型系列的大型语言模型。该系列还包括稳定扩散和现在每天新闻中讨论的所有其他提示驱动的文本模型。
简单地说,生成模型是一种将一组结构化符号作为输入并生成一组相关的结构化符号作为输出的函数。
以下是结构化符号集合的一些示例:
- 单词中的字母
- 句子中的单词
- 图像中的像素 ❀将许多符号转换为视频 将相关符号集的框架方式不限于计算机程序。您可以编写一个使用规则和查找表的计算机程序,例如 20 世纪 60 年代的聊天机器人。

概念介绍:确定性和随机性
在讨论关系之前,我们先介绍一下本文中会反复出现的两个概念:
- 确定性:确定性过程是指给定情况下的输入,必须达到相同的输出。
- 随机性:随机过程是指当给定输入时,得到的输出具有一定程度的随机性,即有时得到一个这样的输出,有时得到另一种输出。
例如,糖果机是确定性的。如果你投入一美元并转动手柄,你每次都会得到一颗糖果。换句话说,一美元=一块糖果,永远不会改变。
但从另一个角度来看,糖果机也是随机的。如果投入一块钱,转动手柄,每次都可以获得一颗糖果,但是这块糖果的颜色基本上是随机的,每种颜色出现的概率取决于机器内部不同颜色的比例。具有五种不同颜色比例的五种不同糖果机将具有五种不同的颜色输出概率分布。
先把这些关键术语放在一边,我们来谈谈为什么人际关系很难。

关系很重要
符号集合可以通过不同的方式关联起来,关系越抽象和微妙,我们就越需要投入更多的技术来解决必须捕捉这种关系的问题。
1。假设我们将集合 {cat} 与 {at-cay} 关联起来,这是一个标准的“Pig Latin”变换(一种英语游戏,其中英语加点规则改变发音,小孩子经常通过这个秘密交流)游戏),我可以通过简单的手写规则集来管理这种关系。
2。假设我们将集合 {cat} 和 {dog} 连接在一起,那么这两个集合可以在多个抽象级别上相关。
- 作为符号的有序集合(序列),两者都具有三个符号。
- 是三个符号的序列,这两个符号都是单词。
- 顾名思义,都是指生物有机体。
- 作为生物体,两者都是哺乳动物。
- 作为哺乳动物,两者都是家畜。
- 等等。
3。假设我们将集合{猫还活着}与{猫死了}关联起来,那么我们可以使用更多甚至更高阶的项来比较和对比这两个符号序列。
- 所有与猫相关的术语都可以被评估,所有与“活”和“死”相关的术语也可以被评估。
- 在另一个层面上,许多读者会发现我们所说的薛定谔的猫的互文参考。
4。让我们添加另一个关系,{猫未成熟}和{猫成熟}。那么在这里,我们谈论的是身体发展的阶段还是情感发展的状态?
- 因为它是一只猫,所以“不成熟”意味着“年轻”、“孩子”等。
- 如果句子的主语是人,则句子更有可能讨论一些有关适合年龄的行为的情感概念。
读完上面的内容,您可以想象,随着列表项从 1 到 4,符号之间可能的关系会爆炸。随着可能的关系数量的增加,关系本身的抽象性、复杂性和微妙性也随之增加。
如上所述,不同的关系使用不同类别的符号存储和检索(从笔和纸到数据中心)以有用的方式捕获和编码它们。
对于第一个比例,我们只需在一张纸上画一个简单的“猪拉丁”比例即可。任何看到这张图片的人都可以将英语单词转换为“Pig Latin”。但对于第四个例子,我们要思考一个问题:为什么机器学习需要价值数千万美元的资源?
1。我们发现这两个集合之间可能存在的关系就像一个小宇宙。这是一个令人眼花缭乱、紧密相连的概念网络,从简单的物理特性到生物分类学,再到身体和情感发展的微妙概念,一直延伸到抽象的阶梯。
2。一些更抽象的可能关系更有可能出现。因此,我们必须考虑可能的因素。
- 正如我在示例中所说,如果我谈论一只猫,成熟和不成熟更有可能是一组与身体发育相关的术语,而不太可能与情感或智力发展相关。
对于上面#2中提到的概念,“不太可能”并不意味着不可能,特别是如果我们扩展上下文的话。例如,我们额外添加一些词:
- {关于戴帽子的猫:猫成熟了。}
- {关于戴帽子的猫:猫不成熟。}
突然所有的可能性都有了。改变了。这里成熟和不成熟的含义可能是另一个领域。
总结:
- 当符号集之间的关系简单且确定时,您不需要太多的存储或计算能力即可将一组符号与另一组符号关联。
- 当符号集之间的关系复杂且随机时,将一组符号与另一组符号关联需要投入更多的存储和计算能力,以更丰富、更复杂的方式关联这些组。

概念介绍:概率分布
高中化学曾经介绍过一个帮助我们思考生成式AI的概念:原子轨道。
原子轨道是指原子核外的空间中电子更容易出现的区域。不同能级的电子具有不同形状的轨道,这意味着它们可以出现在不同的区域。
下图是氢原子的运动轨迹:
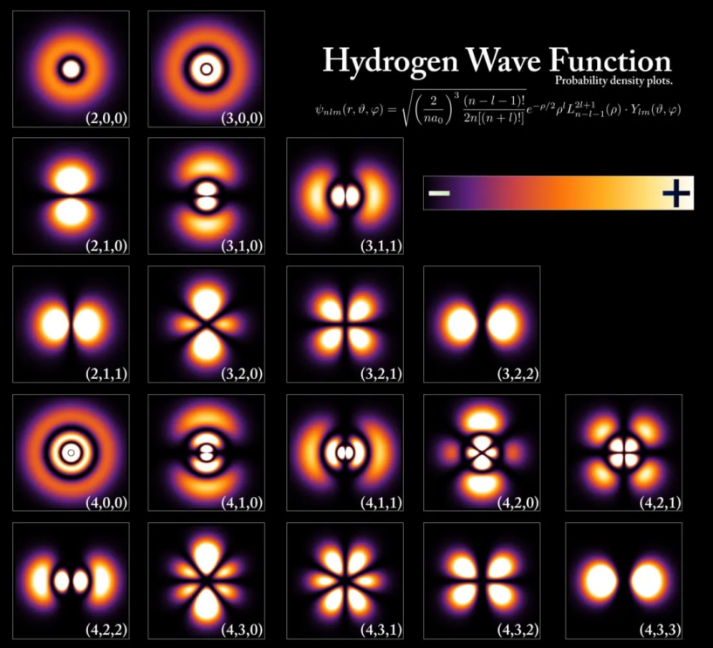
挑出一个来看看:

上图中的运动轨迹,如果用小于电子的东西戳原子,越亮该区域,你击中电子的概率就更高。对于图像中的黑色区域,并不意味着找到电子的概率为零,而只是意味着电子出现在该区域的概率低至几乎为零。
这些轨道是概率分布,它们有特定的形状,上图中的轨道就像四个花瓣,所以如果你看这四个区域之一的一个点,你更有可能找到一个电子,而黑色区域则相反。
以上就是你需要了解的量子化学知识,也是你目前需要了解的全部背景知识。接下来我们来谈谈ChatGPT。

ChatGPT 不了解真相,也没有意见
您可以想象,使用像 ChatGPT 这样的模型,模型可以生成的所有可能的文本位(从几个愚蠢的单词到整个连贯的文章)都是点概率分布,就像我们上面讨论的氢原子轨道中电子的分布位置一样。
当您在ChatGPT的输入框中输入一组单词时,例如:“告诉我关于一只猫在装有一瓶毒药和一些放射性物质的盒子里的情况”,您可以点击“提交”将按钮的操作视为进行观察,这会导致波函数崩溃并产生一组符号(只是许多可能的集合中的一个)。
一些读者可能会意识到文本到文本的大型语言模型实际上在概率空间中找到一个单词并将它们组合成一个句子。但是,在这个抽象级别上,“潜在空间是指模型可以输出的所有单词的多维空间”和“潜在空间是指所有可以发送的单词序列的多维空间”。为了方便读者理解并最小化复杂性,我们在这里使用后一个定义。
有时发短信会带你到概率分布中的一个点,对应的集合是是{猫还活着},有时你会到达另一个点,例如{猫还活着}死了}。
注意,上面的输入符号也可以带你到模型潜在空间中的一个点,其对应的集合是{ph'nglui mglw'nafh Cthulhu R'lyeh wgah'nagl fhtagn},尽管这种可能性几乎是零。这完全取决于文本输入标记中概率分布的形状以及计算机的随机数生成器。
重点是,在这个例子中我们经常说语言模型“知道”猫的状态(活着或死了),但这并不重要。模型是否对猫以及对环境的各种处理方式有一定的了解,其实是从属的。
更好的理解方法是从这个角度来看:在模型可以产生的所有符号集合的空间中(从乱码集合到莎士比亚语料库),在模型的某个区域中找到的符号概率分布集合,我们人类理解为猫还活着。在同一概率空间中的相邻区域中也存在符号集,我们人类将其理解为“猫死了”。
以下是我们在 ChatGPT 的潜在空间(即可能的出口空间)中可以遇到的一些与猫相关的符号集合:
- {猫从睡梦中醒来,眨了眨眼睛。}
- {轻柔的呼吸声当薛定谔打开盒子时,睡猫的头像向他打招呼。}
- {是的,他们把他抓死了。}
- {“我杀了我最喜欢的猫!”薛定谔尖叫着从盒子里拖出宠物的尸体。}
- {帕奇斯从上方看着这一幕,他的星猫形态在天花板附近盘旋,而他的主人从盒子里抬起了毫无生气的尸体并哭泣。}
当使用不同的入口时 set 拟合模型时,遇到某些输出集的概率可能会更高,但理论上很可能会遇到所有输出集。
因此,当你我与ChatGPT就一个事实进行互动时,例如孟加拉虎是否濒临灭绝,我们不应该假设ChatGPT是一个拥有个人经验的实体,或者ChatGPT了解有关孟加拉虎的任何信息。它告诉你和我有些矛盾,它不能被认为是对他们任何一个说谎。
相反,我们应该认为,通过我的短信,我观察到了与孟加拉虎的一组事实和概念相对应的概率分布中的一个点,并且您也做了同样的事情。我们两个人得到了不同的单词序列,这些单词序列似乎代表了不同的事实。例如,它告诉我这只老虎濒临灭绝,但它告诉你这只老虎很常见。这是因为我们两个碰上了概率分布。在不同的叶中,并在不同的叶中发现了不同的点。
- 我在概率分布中标注的注释中包含了一些单词,按照人类的理解,这意味着孟加拉虎濒临灭绝。
- 你粘贴的概率分布中的注释包含许多单词,根据人类的理解,这些单词意味着孟加拉虎的数量过多。
那么,我们该如何解决这个问题呢?
考虑到现实情况是孟加拉虎确实处于灭绝的边缘,我们需要删除你在概率分布中放入的补丁(即孟加拉虎数量过多),或者至少降低概率。

幻想:功能还是错误?
当大型语言模型输出的单词序列与现实情况不符时,我们说该模型产生了“幻觉”。
目前我们有一套方法可以帮助我们塑造大型语言模型输出的概率分布,即使某些区域更小或更不密集,而某些区域更大或更密集:
1 训练
2. 微调
3. 人类反馈强化学习 (RLHF)
我们可以在高质量数据上训练基础模型。我们所说的高质量数据是指作为人类观察者的符号集合,这些符号有意义且与世界真相相符。通过这种方式,经过训练的模型的行为就像一个原子,其轨迹形状如我们所知。
接下来,我们使用模型并识别在观察过程中我们预计不会在输出空间中遇到的区域,然后使用更有针对性、精心设计的训练数据对模型进行微调。此调整将缩小补丁的一部分并扩大补丁的一部分。同时,我们希望在对patch的形状进行多次微调后,一次又一次地减少波函数,以获得我们更满意的输出。
最后,我们利用带有人类反馈的强化学习,引入一些人为因素来帮助我们调整模型概率空间的形状,使其尽可能覆盖可能的输出空间中与“真相”相对应的点同时,与“假”事物对应的点也没有被覆盖。当这一步正确完成时,模型概率空间中的所有观察结果都会成为我们的“真相”点。
关于本节的内容,我个人主要有两个问题:
1。我们所说的这个“观察者”是谁呢?是负责解释模型结果并判断是非的人吗?他们是聪明还是愚蠢?他们真的对真相感兴趣,还是只是想塑造这个模型的概率分布以实现自己的目标?
2。如果我有幸成为决定模型输出是否真实的观察者,我真的只想要真相吗?如果我想要一个模型给我讲一个关于独角兽的睡前故事,我是否希望它模仿一位著名主持人给我讲这个故事?一般来说,模型创建特征的能力并不是非黑即白的,不是吗?
这些问题是“幻觉”问题的核心,但这些不是技术问题,而是语言哲学、解释学、政治的问题,最重要的是:这是一个权力问题。

ChatGPT 对您一无所知
ChatGPT 的交互体验非常强大,但实际上它只是一个用户界面,很像一个计算器应用程序,看起来像一个小型物理计算器。
虽然您认为模特试图像您了解她一样了解您,但随着对话的进展,你们俩都会继续更好地了解对方。但这种情况并非如此。
您需要完全摆脱您正在与 ChatGPT 对话的想法,为此,您需要掌握最后一个概念:令牌窗口。
ChatGPT 之前的语言模型
使用本文介绍的普通语言模型,您为模型提供一组输入,它执行概率运算,然后给出输出。输入进入模型的标记窗口。
- 这里的“代币”指的是本文一直在谈论的“符号”。我试图避免使用术语,所以我说“令牌”,但实际上所有接收和输出的模型都是令牌。
- “窗口”是模型可以接收并转换为一系列输出的令牌数量。
因此,当我在 ChatGPT 之前使用大型语言模型时,我将令牌放入令牌窗口中,模型返回潜在空间中靠近我放入的令牌的点。
关键是概率空间不会根据我放入窗口中的棋子而改变形状。当我与之交互的窗口从一个窗口更改为另一个窗口时,模型的权重保持不变,也就是说,模型不记得前一个窗口的内容。
你可以这样想:每次我将令牌放入模型的窗口并单击“提交”时,就好像我在街上遇到模型并第一次与它交谈一样,而且确实如此不记录任何相关内容。有关与我互动的历史或信息。
另一个不太完美的类比:每次我将特定的尖端和种子送入稳定扩散中时,我都会得到相同的图像。每个提示和种子组合都会将我带到潜在空间中特定图像所在的点,如果我继续给它相同的输入,我仍然会得到相同的结果。我与模型没有共同的历史,并且稳定扩散不会“了解”有关我的任何信息。
最终结果是,一旦模型被训练,唯一可用的信息仅限于我放入令牌窗口中的信息。如果我将包含我的婚姻状况的单词序列输入到符号窗口中,模型将采用这些序列并返回输入序列旁边的潜在空间中的一个点,该点表示我在符号窗口中提供的相同单词序列。这实际上是相关信息。

虚假个性是ChatGPT的一项很酷的技能
ChatGPT是一个大语言模型,具有大的令牌窗口,这使得体验更具交互性,让用户感觉像在真正的对话。
现在,让我们实际尝试一下ChatGPT的用户界面。假设我打开浏览器并启动 ChatGPT 会话,如下所示:
我:怎么了伙计。 (嘿,你最近好吗?)
ChatGPT:没什么。你怎么了? (还是那样。你好吗?)
我:呃,我的猫刚刚在实验室事故中死了。事故。)
ChatGPT:听到这个消息我感到非常遗憾。 (听到这个消息我很遗憾。)
我:是的,这很糟糕。不过,我已经在收容所挑选了一只狗。我今天下午去接他。
ChatGPT:太令人兴奋了!我确信您的新狗将像您已故的猫一样成为您的好伴侣。 (太棒了!我相信你的新狗会像你现已去世的猫一样成为你的好伴侣。))
我们将此会话分成几个令牌窗口,然后将它们插入到模型中:
令牌窗口 1:
{怎么了,伙计。}(嘿,你好吗?)❀O 1:
{不多。你怎么了?}(还是那样。你好吗?)
令牌窗口 2:
{我:怎么了,伙计。 ,你好吗?)
ChatGPT:不多。你怎么了? (还是那样。你好吗?)
我:呃,我的猫刚刚在实验室事故中死了。}(哦,我的猫刚刚在实验室事故中死了。)猫刚刚在实验室事故中死了。)
出口 2:
{我真的很难过。}(我真的很难过。)
令牌窗口 3:
{我:怎么了,伙计。 (你好,你好吗?)
ChatGPT:不多。你怎么了? (还是那样。你好吗?)
我:呃,我的猫刚刚在实验室事故中死了。 (哦,我的猫刚刚在实验室事故中死亡。)
ChatGPT:听到这个消息我真的很遗憾。 (听到这个消息我很遗憾。)
我:是的,很糟糕。不过我已经在收容所选到一只狗了。}他。)
3号出口:
{太刺激了!我确信您的新狗将像您已故的猫一样成为您的好伴侣。}(太棒了!我确信您的狗将像已故的猫一样成为您最好的伴侣。)
看到了吗? OpenAI 不断地将每个对话的输出添加到现有输出中,以便令牌窗口的内容随着对话的进行而不断增长。
每次我按“发送”时,OpenAI 不仅会将我的最新输入发送到模型,还会将会话中之前的所有对话添加到令牌窗口,以便模型可以访问整个“聊天历史记录”,并引导我找到概率空间中的正确补丁。
换句话说,随着我与 ChatGPT 的会话的进展,我给模型的“文本提示”变得更长、信息更丰富。然后,在第三次交换中,ChatGPT“知道”我的猫死了,并且能够正确响应,正是因为 OpenAI 秘密地将我们的整个“聊天”历史记录放入每个新的令牌窗口中。
但是除了我们的聊天记录之外,这个模型不可能“知道”关于我的任何事情。因此,令牌窗口是一个共享的、可变的状态,模型和我不断修改它,而内容就是模型用来查找相关单词序列来响应我的内容。
总结一下:
- 模型的重量在正常使用过程中是不变的。这个权重决定了上面的概率分布,并代表了模型“知道”的关于世界的一切。
- 我可以向模型提供新的“事实”,这些信息是我输入到令牌窗口中的信息,并且模型基于该信息产生新的输出。
如果您了解了以上所有内容,您就会明白即将发布的 OpenAI 模型版本中的 32K 代币窗口非常重要。这个符号窗口足以让模型加载新的事实,例如客户服务历史记录、书籍章节或脚本、动作序列等等。
随着代币窗口变大,预先训练的模型可以动态“学习”更多信息,从而解锁更多新的人工智能功能。
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。






作者文章
- 用小程序学英语到底有没有用?适合哪些人?避坑指南加靠谱用法有吗? 2周前 (05-22)
- 2024-2025做通用和本地生活小程序没人看没人下单怎么办?试试这6个小成本留客转化型技巧 2周前 (05-22)
- 做小程序英文翻译避不开哪些坑?怎么翻才能吸引海外用户留存? 2周前 (05-21)
- Vue3 Composition API watch开启deep后踩过哪些坑?如何高效用它处理深层数据监听? 2周前 (05-19)
- Vue3中watch监听props时,deep:true到底该不该随便开? 2周前 (05-19)