 code前端网
code前端网Python量化策略算法性能提升指南
性能问答
Python可以说是2016年国内量化投资圈的热门,目前整个生态链已经初具规模:❙ vn.py, easytrader, at_py
用户性能问题逐渐成为整个社区越来越关注的焦点。我经常见到新手并问:用Python写的量化交易程序很慢吗?
Python在他们心目中大概是这样的:![]()
(即使是一辆老自行车,我也严重怀疑这辆自行车是否能开好)
网上有很多关于Python程序提高性能的文章。但大多数都是不系统的,只是非常简单的例子。它们总是让人感觉有点粗糙,与现实生活中的应用相距甚远。
作者看到了填补市场空白的机会(简介)! !
在这篇文章中,我们用实际例子来展示一段量化策略中常用的代码如何能够提速一百倍。 ![]()
常用代码
下一个要使用的例子是,我相信几乎所有量化策略的作者都写过类似的代码:求时间序列的算术移动平均值。
这里我们首先初始化我们将使用的数据:100,000个数据点(随机整数),以500的计算窗口运行算术移动平均,并运行每个算法10次以找到平均时间。
# 这个测试目标在于仿造一个类似于实盘中,不断有新的数据推送过来,
# 然后需要计算移动平均线数值,这么一个比较常见的任务。
from __future__ import division
import time
import random
# 生成测试用的数据
data = []
data_length = 100000 # 总数据量
ma_length = 500 # 移动均线的窗口
test_times = 10 # 测试次数
for i in range(data_length):
data.append(random.randint(1, 100))
在每次测试中,我们都会通过测试数据来模拟真实市场中的策略不断接收新数据推送的情况(事件驱动回测模式也是如此),并计算移动平均线。连续存储在列表中并作为最终结果返回。
测试电脑配置:Core i7-6700K 4.0G/16G/Windows 7。
第一步,我们用最简单最基本的方式计算移动平均值:![]()
个人时间消耗指的是通过整个测试数据计算移动平均所需的时间,单个数据点耗时是指遍历过程中每个数据点的平均计算时间。以下算法使用最后10条移动平均线进行比较,以保证计算结果的正确性。 ?这个测试结果不能称得上很好,但也可以接受。考虑一个简单的双移动平均线CTA策略(Double SMA Strategy),每个数据点到达后,进行两次移动平均线计算。一般情况下,移动平均线窗口不超过500,比较两个移动平均线交集的算法较小。该策略的信号计算时间估计为 30 微秒,这对于通常在 1 分钟线甚至更长时间范围上运行的策略来说绰绰有余。
现在我们已经有了一个起点,让我们尝试逐步提高性能。
尝试 NumPy?
当使用Python不足以进行数值运算时,很多人首先反应是使用NumPy:在之前的ma_basic中,较慢的部分是在添加每个新数据点后遍历并计算平均值。数据窗口。代码,然后切换到使用 numpy.array 进行求和应该可以提高性能,对吧? UMa_numpy_wrong测试结果
- 单次:2.11879999638秒
- 单数据点消耗:21.2944723254微秒
WTF?!到达速度快了 2 倍)!
这里的写法是对NumPy非常常见的滥用。问题在于:
data_array = np.array(data_window)
由于NumPy中的大部分对象实现都比较复杂(提供了很多函数),所以创建和销毁对象的成本非常高。上面的代码意味着,对于每个要计算的新数据点,必须创建一个新的矩阵对象,该对象仅使用一次后就会被销毁。使用 ary.mean 求平均值方法所实现的性能改进不值得创建和销毁数组对象的额外开销。
正确的用法是使用np.array作为data_window时间序列容器。每次计算新的数据点时,都会利用底层数据偏差来更新数据:
# numpy的正确用法
def ma_numpy_right(data, ma_length):
ma = []
# 用numpy数组来缓存计算窗口内的数据
data_window = np.array(data[:ma_length])
test_data = data[ma_length:]
for new_tick in test_data:
# 使用numpy数组的底层数据偏移来实现数据更新
data_window[0:ma_length-1] = data_window[1:ma_length]
data_window[-1] = new_tick
ma.append(data_window.mean())
return ma
ma_numpy_right测试结果
- 单次耗时:0.614300012589秒:6 6 7点 3点消耗。 7325微秒
速度比ma_basic大约快2倍。看来这也适用于 NumPy。
JIT神器:Numba
关注Python性能的朋友应该都听说过PyPy这个名字。 PyPy 内置的 JIT 技术号称可以通过重新设计的 Python 解释器将 Python 程序加速数十倍(相比 CPython),但遗憾的是由于兼容性问题,它并不适合量化策略开发。
幸运的是,我们还有 Anaconda 的 Numba。 Numba 允许用户使用基于 LLVM 的 JIT 技术来本地优化程序(函数)中想要提高性能的部分。同时,Numba 的设计理念也更加务实:可以直接在 CPython 中使用,并且与其他常用的 Python 模块有很好的兼容性,最重要的是,使用方法非常万无一失:
# 使用numba加速,ma_numba函数和ma_basic完全一样
import numba
@numba.jit
def ma_numba(data, ma_length):
ma = []
data_window = data[:ma_length]
test_data = data[ma_length:]
for new_tick in test_data:
data_window.pop(0)
data_window.append(new_tick)
sum_tick = 0
for tick in data_window:
sum_tick += tick
ma.append(sum_tick/ma_length)
return ma
ma_numba 测试结果
- 一次性耗时:0.043700003624 秒
- 一个数据点耗时:0.439196016321 微秒 只需添加 @numba.jit 这行代码,性能就提升了 26 倍!根据修改的代码行数,这可能是最具成本效益的优化解决方案。
重写算法
从编程哲学的角度来看,提高计算机程序速度的基本原则之一就是降低算法的复杂度。看到这里,估计有些量化老手ma_basic已经不高兴了。如果我们创建一个复杂度为 O(N) 的算法来计算平均值,为什么我们不能缓存求和结果并将复杂度降低到 O(1)?
› 行动是最强大的力量! ! !
(索罗斯:其实我是哲学家。)
重写算法后,ma_online在没有JIT的情况下击败了ma_numba,性能提升了33倍(相比ma_basic)。如果添加 Numba 会发生什么?
› 相比ma_Numba vs ma_basic 还是提升了40倍,提升不是那么明显。当然,哲学的力量还是太强大了。这个利器:Cython
到目前为止我们在纯Python环境下使用优化方法已经达到了极限。如果我们想更进一步,我们需要利用Python胶水语言的特性:使用其他扩展语言。由于CPython虚拟机开发语言为C,因此提高性能的扩展语言主要选择C/C++。相关工具有ctypes、cffi、Swig、Boost.Python等,虽然功能很强大,但是以上工具都没有。特别要求用户具备C/C++语言相关的编程技能,这对于很多Python用户来说是困难的。
幸运的是,Python 社区对懒惰的追求永无止境,终极武器 Cython 诞生了。 Cython的详细介绍可以在官网找到。简单来说,它的主要目的是让用户以非常接近Python的语法实现非常接近C的性能。
我们先尝试最简单的方法:不修改任何代码,将函数放在 .pyx 文件中,然后调用 Cython 将其编译成 .pyd 扩展模块。 ?编译后性能提升了1倍左右,但这与我们之前实现的优化效果相比可以说是不太理想。
在Cython官方快速入门中,第一步是教用户如何编译程序,第二步是使用静态声明来提高性能,所以下一步是:静态声明+快速算法。 ? ! !它几乎比 ma_online_numba 快 3 倍。 98纳秒的计算速度足以满足大多数毫秒级高频策略的延迟要求。
主要因素是这一行:
cdef int sum_buffer, sum_tick, old_tick, new_tick
当函数中使用的变量是静态声明的,当Python不再需要int对象类型时,Python不再需要对象类型。编译由于其独特的功能,整个函数可以优化为高度静态的类语言实现,达到接近C语言性能的性能。结合复杂度为 O(1) 的快速算法,性能提升如此之大也就不足为奇了。 。
附上一份简单的Cython使用指南:
- 将需要用Cython编译的函数放入.pyx文件中,如test.pyx
- 创建一个cmd.py来设置相关的编译选项。或者通过终端输入test.pyx和setup.py所在的文件夹就会出现在当前文件夹test.pyd
- 打开python,像其他模块一样加载(导入)test.pyd就从坑里出来了“100倍加速”并不一定是标题党。
最终算法性能对比图:
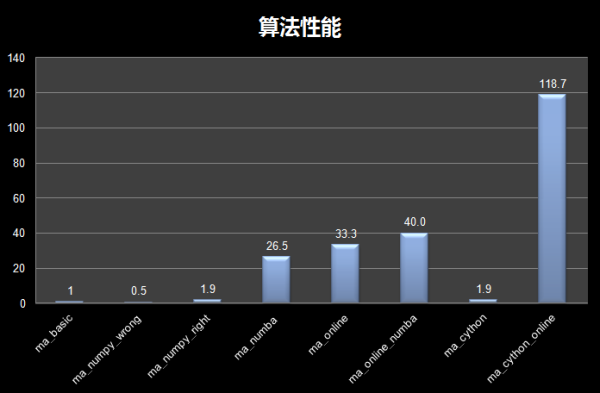
最后总结:
- 当你在实际工作中面临Python程序性能优化的需求时,第一件事就是找到程序中延迟较大的热点代码,只有找到问题,解决方案才有意义;
- 所有的优化工作都应该在测试的基础上逐步进行。同样的优化方法对于不同类型的代码可能会产生完全相反的效果。同时,错误的优化方法也可以最好不要优化(如ma_numpy_wrong);
- Numba,只需添加一行代码即可加速(@numba.jit),无疑是最具成本效益的优化方案,值得首先尝试。但是,您必须注意 numba JIT 技术的局限性。大(主要针对数值计算相关的逻辑);
- 学习如何降低算法复杂度,编写更高效的算法,可以潜移默化地提高你的编程水平,从长远来看,这对于Quants或程序员来说是最有价值的优化方法;
- 如果其他优化方法无法达到您满意的性能水平,请尝试Cython(记得添加静态声明);
- 良好的程序架构规划非常重要,不同函数的计算也是。将逻辑分解为不同的函数,适当减少每个函数的代码行数,有助于后期的性能优化工作。
文章的所有代码以及用于测试的Jupyter Notebook都可以从vn.py项目的Github存档中下载。记得点击星星哦!
来源:使用 Python 的交易者
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。






作者文章
- 用小程序学英语到底有没有用?适合哪些人?避坑指南加靠谱用法有吗? 3周前 (05-22)
- 2024-2025做通用和本地生活小程序没人看没人下单怎么办?试试这6个小成本留客转化型技巧 3周前 (05-22)
- 做小程序英文翻译避不开哪些坑?怎么翻才能吸引海外用户留存? 4周前 (05-21)
- Vue3 Composition API watch开启deep后踩过哪些坑?如何高效用它处理深层数据监听? 4周前 (05-19)
- Vue3中watch监听props时,deep:true到底该不该随便开? 4周前 (05-19)