 code前端网
code前端网MongoDB5.0新功能“时序”分析:采集性能与IOT场景设计
1. MongoD B新功能“计时”剖析
- MongoD B计时采集是MongoD B 5.0新推出的功能,可以快速将一定时间段的数据采集写入磁盘,并提供时间序列的快速检索。
- 与常规集合相比,时序集合在数据插入过程中会根据时间维度自动将数据组织成最优的存储格式,这也提高了下游应用查询时序数据的效率。
- MongoD B 传统序列模式:
假设我们有一个传感器,每分钟测量一次温度并将其存储在数据库中,我们需要将数据流写入数据库:
{_id: ObjectId(), deviceid: 1, date: ISODate ("2019-11-10"), samples : [{ temperature: 10, time: 1573833152},]},
{_id: ObjectId(), deviceid: 1, date: ISODate ("2019-11-10"), samples : [[ temperature: 15, time: 1573833153},]},
{_id: ObjectId(), deviceid: 1, date: ISODate ("2019-11-10"), samples : [[ temperature: 14, time: 1573833154},]},
{_id: ObjectId(), deviceid: 1, date: TSODate("2019-11-10"), samples : [[ temperature: 20, time: 1573833155},]}- 桶模式设计数据模型:
{
_id: objectId(),
deviceid: 1,
date: ISODate ( "2019-11-10") ,
first: 1573833152,
last: 1573833155,
samples : [
{ temperature: 10, time: 1573833152},
{ temperature: 15, time : 1573833153},
{ temperature: 14, time: 1573833154),
{ temperature: 20, time : 1573833155}
]
}字段说明:
- id - 文档ID,此ID是唯一的
- deviceld - 查询设备ID
- date - 采样日期;我们可以将它们保存在这里以简化聚合
- first - 存储桶中加载的最旧数据的时间戳
- last - 存储桶中加载的最新数据的时间戳
- samples - 数据容器 vano 正在使用的广告案例:
- 节省数据和索引大小
- 简化数据结构
- 可按时间维度收集需要采集的数据,方便快速范围加载
- 提高数据写入速度
2. 如何利用时间MongoDB中的series - 将指定创建的集合显示为时间序列集
db.createcollection ( "weather", { timeseries: { timeField: "timestamp", metaField: "metadata", granularity: "hours" } }字段含义介绍:
- timeField是时间参数,必须是BSON数据。
- metaField 影响维度基数。一个好的metaPole应该选择低功率和选择性指标。高功率必然带来性能的下降。
- 粒度为聚合粒度参数(可选)。数据库计算数据聚合和存储的时间段。该参数影响性能但不影响功能。
- expireAfterSeconds影响数据过期,默认是通过每60s检测一次来实现的。过期时间可配置
- CRUD 操作
- 新增:一次性插入或批量插入集合(与传统集合没有区别)
- 删除(跳过)
- )更改‸‸‸‸更改:
计算时间序列采集周期的平均值(聚合查询):
db.weather.aggregate([ { project: { date: { $dateToParts: { date: "$timestamp" } }, temp: 1 }, { $group: { _id: { date: { year : "$date. year", month: "$date.month", day : " $date.day" } avgTmp: { $avg: "stemp"} } ])- 注:
- 基础时间序列采集存储库仍然是WiredTiger;
- 没有太多适合查询时间序列的新语法,各种聚合仍然需要聚合传递;
- 时间序列聚合根据常见的查询方式优化了数据存储模型。如果您对索引中的元字段有自己的过滤需求,通常可以创建二级索引;
- MongoDB的时间序列集合在更新和删除时必须添加特定条件。
- 当前版本,时序集合不支持分片(6.0支持分片)。 ? zstd和zlib算法,对比以往线上数据空间的实际大小和实际磁盘空间消耗,可以得出以下结论:
压缩算法 实际数据量 实际磁盘空间功耗 压缩算法 3.5T 1-1.5T zstd 压缩算法 3.5T0.gorT‶lib-0.gorT‶6 3.5T。 5T 0.5-0.7T Hbase默认使用快速算法,MongoDB时间序列集合默认使用zstd压缩算法,因此同等数据量下MongoDB的磁盘占用率更低。
- MongoD B 计时使用限制:
- 客户端加密
- ChangeStream
- Relndex 重建索引 s更新限制 ♝♸ IV.MongoDB时序IOT场景设计
场景需求:
数据质量,实时kafka数据消耗,计算流后需要显示数据,如图流程图:- 采集时间序列
- 读写分离
- ChangeStream重定向查询
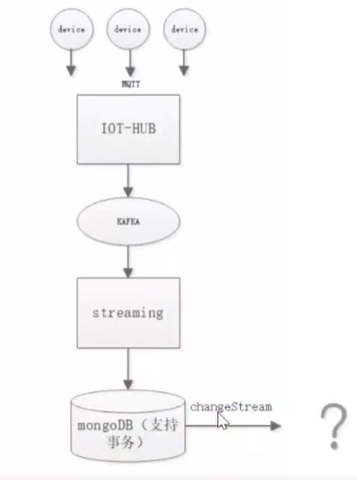
- 过期后清理数据:
- 可以使用时间序列集合的原始TTL索引进行自动过期。
- 您可以用新集合替换旧集合,也可以直接删除旧集合。
作者:王丁
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。
相关文章





