1。概念:scrapy是一个用python编写的爬虫框架,用于爬取网络数据并提取结构数据的框架。使用 Twisted 的异步网络框架来加速下载。 2。特点:爬取速度快,代码量小。 3。工作流程 索引器工作流程:运行 URL — 下单 URL...
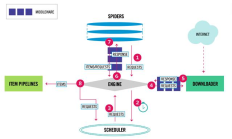
Scrapy的架构图帮助我们了解其背后的整个工作流程,是我们深度掌握以及Scrapy定制开发的重要基础。 -ins。另外,我们也会从总体的角度来回顾一下Scrapy框架源码。接下来的章节会涉及到Scrapy源码进行讲解,所以首先需要查看Sc...
Scrapy 是一个爬虫框架,可以帮助简化网络爬虫开发,用最少的代码实现爬虫项目,并具有完整的爬虫功能。 1。爬虫简介网络爬虫是一段具有特殊含义的代码。它的工作是在浏览器中模拟用户操作,发送HTTP请求,接收数据,然后分析并保存数据,以方...
如何在Scrapy中使用Xpath选择器从HTML中提取目标信息。在Scrapy中,它提供了两种数据提取方法,一种是Xpath选择器,另一种是CSS选择器。在本课中,我们将首先关注 Xpath 选择器,仍然使用 伯乐 Online 作为示例...
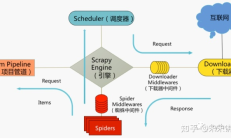
在了解 Item Pipeline 之前,我们先看一下下图。 您可以看到项目管道位于上图的最左侧。 Item pipeline的主要任务是处理Spider从网页检索到的item。因此,Item Pipeline的主要任务是清理、验证和存储...
Django的ORM框架与数据库的映射关系是这样的(如下)。这是一张表之间的关系,那么多张表呢?在关系数据库中,并非所有数据通常都位于同一个表中。这需要更多的内存空间。表连接通常用于解决关系数据库中的问题。 表格以什么方式相关? 一对一:...
1。 Scrapy框架简介Scrapy是:用Python开发的快速高级屏幕抓取和网页抓取框架用于从网页中爬取数据并提取结构。只需要实现少量代码即可实现快速浏览。 2.工作原理关于Scrapy框架的工作原理,看下图就可以了(其实原理相当复杂,...
scrapy如何查象。我们首先以爬取站长素材中的高清图片为例。我们将解释今天的步骤。在我们解释之前,让我们先弄清楚总体思路。 1。scrapy对于图像爬取的主要思想是什么? scrapy爬取图像和文本信息的前几步是相同的。他们需要经历以下步...
Scrapy是学习爬虫非常重要的一环。它可以快速帮助我们筛选出我们想要的数据信息,因此本课我们将重点介绍如何使用scrapy。 1。如何搭建scrapy框架第一步我们首先需要安装scrapy。 这一步就不过多介绍了。前面的课程也讲解了如何...
使用scrapy爬取数据。 1。浏览数据的主要思路我们从这个URL(https://so.gushiwen.cn/shiwenv_4c5705b99143.aspx)浏览这首诗的标题和诗句,然后保存在文件夹中,2。 scrapy爬虫案例分析...
分享好东西,收藏啦!
 code前端网
code前端网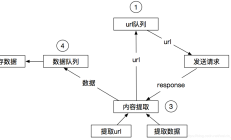





 css动画无限循环 3年前 (2023-09-07)
css动画无限循环 3年前 (2023-09-07) 新手必须掌握的 10 个 CSS 技能 3年前 (2023-09-07)
新手必须掌握的 10 个 CSS 技能 3年前 (2023-09-07) CSS 显示属性 3年前 (2023-09-07)CSS calc() 函数 3年前 (2023-09-07)
CSS 显示属性 3年前 (2023-09-07)CSS calc() 函数 3年前 (2023-09-07)
分享好东西,收藏啦!