 code前端网
code前端网我们从出色的 Scrapy 数据和网站爬行示例开始
![]()
1。 Scrapy框架简介
Scrapy是:用Python开发的快速高级屏幕抓取和网页抓取框架用于从网页中爬取数据并提取结构。只需要实现少量代码即可实现快速浏览。
2.工作原理
关于Scrapy框架的工作原理,看下图就可以了(其实原理相当复杂,三言两语无法说清楚,有兴趣的读者可以进一步阅读更多相关文章来了解,本文不会过多解释。3.使用入门
3.1 安装
第一种:使用命令行方式使用 pip 安装:
$ pip install scrapy
第二种:先下载后安装:
$ pip download scrapy -d ./
# 通过指定国内镜像源下载
$pip download -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy -d ./
进入下载目录,执行以下命令安装:
$ pip install Scrapy-1.5.0-py2.py3-none-any.whl
3.2 使用
使用大致分为以下四个步骤 1 创建低质量工程
scrapy startproject mySpider
2 创建浏览器
scrapy genspider demo "demo.cn"
3 提取数据❙❀4 保存数据 ♷ 3.3 运行程序
在命令中启动浏览器 scrapy crawl qb # qb爬虫的名字
scrapy crawl qb # qb爬虫的名字
在 Pycharm 中启动爬虫
from scrapy import cmdline
cmdline.execute("scrapy crawl qb".split())
4. 基本步骤
Scrappy 使用爬虫框架的具体步骤如下:
“
- 选择目标网站
- 定义要爬取的数据(通过Scrapy Items完成)
- 编写spider来提取数据
- 运行spider并获取spider”
5.目录文件说明
创建了一个粗略的项目后,我们继续创建spider。目录结构如下:
 简单想象一下各个主文件的作用:
简单想象一下各个主文件的作用: 》scrapy.cfg:项目配置文件
将是一个项目模块P。从这里引用
mySpider /items.py:目标项目文件
mySpider/pipelines.py:项目
的管道文件我的文件pyder/项目设置❙mySpider/settings./spiders/:仓库爬虫代码目录
”5.1 文件 scrapy.cfg
项目配置文件。这是文件内容:
# Automatically created by: scrapy startproject # # For more information about the [deploy] section see: # https://scrapyd.readthedocs.io/en/latest/deploy.html [settings] default = mySpider.settings [deploy] #url = http://localhost:6800/ project = mySpider5.2 mySpider**/**
项目 Python 模块,代码将从此处引用
5.3 mySpider/items.py 项目
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class MyspiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass定义 Garbage Items 模块,示例: name = scrapy.Field()
5.4 mySpider/pipelines.py
这是一个管道文件⓽当item在spider中时调用管道,收集后会传递到item管道( pipeline),它将按定义的顺序处理项目。每个 Pipeline 项都是一个 Python 类,它实现简单的方法,例如决定是否丢弃和保存该项。以下是项目提要的一些典型应用:
- 验证爬网数据(检查项目是否包含某些字段,例如名称字段)
- 检查重复数据(并丢弃)
- 将爬网结果保存到一个文件或
5.5 mySpider/settings.py
数据库中包含项目设置的文件
# Scrapy settings for mySpider project ... BOT_NAME = 'mySpider' # scrapy项目名 SPIDER_MODULES = ['mySpider.spiders'] NEWSPIDER_MODULE = 'mySpider.spiders' ....... # Obey robots.txt rules ROBOTSTXT_OBEY = False # 是否遵守协议,一般给位false,但是创建完项目是是True,我们把它改为False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # 最大并发量 默认16 ...... #DOWNLOAD_DELAY = 3 # 下载延迟 3秒 # Override the default request headers: # 请求报头,我们打开 DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } # 爬虫中间件 #SPIDER_MIDDLEWARES = { # 'mySpider.middlewares.MyspiderSpiderMiddleware': 543, #} # 下载中间件 #DOWNLOADER_MIDDLEWARES = { # 'mySpider.middlewares.MyspiderDownloaderMiddleware': 543, #} ...... # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'mySpider.pipelines.MyspiderPipeline': 300, # 管道 #} .......椭圆省略代码,通常列出重要的点和注释
我的蜘蛛。 /:浏览器代码
import scrapy class DbSpider(scrapy.Spider): name = 'db' allowed_domains = ['douban.com'] # 可以修改 start_urls = ['http://douban.com/'] # 开始的url也可以修改 def parse(self, response): # pass6存放的目录。 Scrapy shell
Scrapy终端是一个交互式终端。我们可以尝试在不运行蜘蛛的情况下调试代码。它还可用于测试 XPath 或 CSS 表达式以了解它们如何工作,从而使网页更易于抓取。数据是从数据库中提取的,但一般用得不多。如果有兴趣,可以查看官方文档:
官方文档
http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.htmlScrapy Shell 会根据下载的页面自动创建一些合适的对象,比如 Response 对象和
Selector 对象(用于 HTML 和XML 内容)。- 加载 shell 时,您将获得一个包含响应数据的本地响应变量。输入
response.body并将打印响应的正文。response.headers您可以看到响应标头。 - 当您输入
response.selector时,您将获得一个使用响应初始化的类似选择器的对象。目前,可以使用response.selector.xpath()或 response .selector.css() 来查询响应 - Scrapy 还提供了一些快捷方式,例如response
。
选择器
“内置Scrapy选择器XPath和CSS选择机制♸” Selector有四种基本方法,最常用的还是xpath:
xpath() :传递 xpath 表达式,返回与表达式匹配的所有节点的选择器列表 - extract():将节点序列化为字符串,并返回列表
- css() :传递 CSS 表达式,返回选择器列表列出与表达式匹配的所有节点。语法与BeautifulSoup4
- re()相同:根据传入的正则表达式提取数据,返回字符串列表
7。案例实践
本节以使用Scrapy抓取大网站数据为例

7.1案例说明
现在我们已经初步了解了scrapy的工作流程和原理,下面通过一个案例来介绍一下爬取Zoku主页上的特色商品信息。如下图所示,小方框就是物品信息。我们需要提取每个项目的六个组件:
- imgLink(链接到打开的图像);
- 姓名(姓名);
- 类型(类型);
- 访客(人气);
- 评论(评论数);
- 点赞数(推荐数)
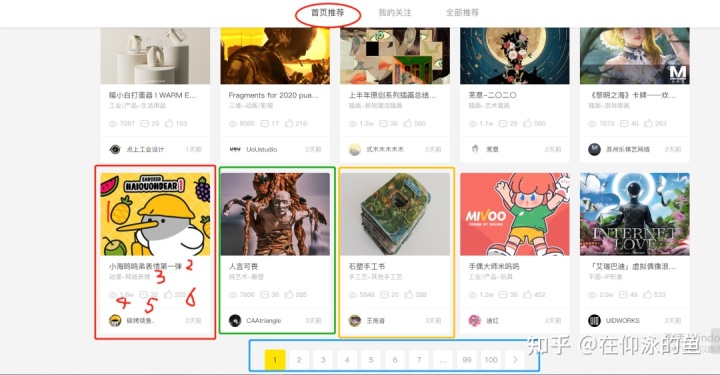 那么就只是页面上的一个项目,我们还要通过翻页的方式实现批量数据采集。?目录结构如下图:
那么就只是页面上的一个项目,我们还要通过翻页的方式实现批量数据采集。?目录结构如下图:
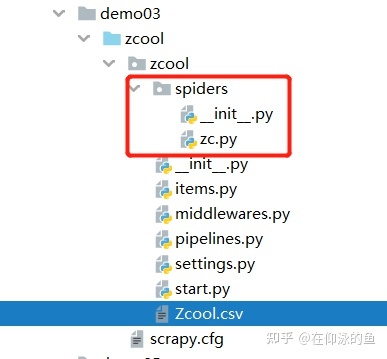
start.py 文件
然后,为了方便操作,在zcool目录下新建一个start文件。并执行初始设置。文件
from scrapy import cmdline cmdline.execute('scrapy crawl zc'.split())settings.py
在这个文件中我们需要进行一些设置
避免程序运行时打印日志信息
LOG_LEVEL = 'WARNING' ROBOTSTXT_OBEY = False添加请求头:♸写入管道:

item.py 文件
import scrapy class ZcoolItem(scrapy.Item): # define the fields for your item here like: imgLink = scrapy.Field() # 封面图片链接 title = scrapy.Field() # 标题 types = scrapy.Field() # 类型 vistor = scrapy.Field() # 人气 comment = scrapy.Field() # 评论数 likes = scrapy.Field() # 推荐人数7.3 从页面中提取数据
首先,我们使用 xpath-helper 在一个很棒的页面上进行测试:文件 z.c 中的
。 中间结果如下图所示:
 没问题,接下来我们分别分析提取不同的信息,
没问题,接下来我们分别分析提取不同的信息, def parse(self, response): divList = response.xpath('//div[@class="work-list-box"]/div') for div in divList: imgLink = div.xpath("./div[1]/a/img/@src").extract()[0] # 1.封面图片链接 ... 2.title(标题);3 types(类型);4vistor(人气);5comment(评论数) .... likes = div.xpath("./div[2]/p[3]/span[3]/@title").extract_first() # 6likes(推荐人数) item = ZcoolItem(imgLink=imgLink,title=title,types=types,vistor=vistor,comment=comment,likes=likes) yield item解释:♝ 解释:♝ 说明:♝方法: S.N.
方法及说明 extract() 返回列表中存储的符合要求的所有数据。 extrah_first() 返回hrefs列表中的第一个数据。 get() 和extract_first()方法返回相同的东西,都是列表中的第一个数据。 getall() 与 extract() 方法相同。返回所有符合要求并存储在列表中的数据。 注意:
“get() 和 getall() 方法是新方法,extract() 和 extract_first() 方法是旧方法。 extract() 和 extract_first() 方法如果无法获取则返回 None。如果无法获取get()或getall()方法,则会显示错误。
”项实例化(yield上方的代码行)
这里我们已经在目录文件配置项文件中设置了。 ,为了存储数据,我们需要在浏览器文件的开头导入此类:
from zcool.items import ZcoolItem,然后使用yield返回数据。
为什么要用return而不是return
毫无疑问不能用return,因为要翻页用return直接退出函数;而对于yield:调用时,函数不会立即执行,而仅返回生成器对象。该函数在迭代期间开始执行,当它返回时,将返回当前值 (i)。该函数将继续循环,直到没有更多的值。 ?由于是页面的批量数据采集,所以代码还是需要修改。翻页有两种方法:
方法一:首先,我们在页面上找到下一页的按钮,如下图所示:页 for 循环 当完成的。
next_href = response.xpath("//a[@class='laypage_next']/@href").extract_first() if next_href: next_url = response.urljoin(next_href) print('*' * 60) print(next_url) print('*' * 60) request = scrapy.Request(next_url) yield requestscrapy.Request():将下一页的URL发送给Request函数,以收集翻页周期中的数据。
https://www.cnblogs.com/heymonkey/p/11818495.html # scrapy.Request()参考链接注意下一页按钮对应属性href的值必须与下一页的URL一致。
方法2:定义一个全局变量count = 0,每次爬取数据页时加1,创建新的URL,然后使用scrapy.Request()运行请求。
如下图所示:
count = 1 class ZcSpider(scrapy.Spider): name = 'zc' allowed_domains = ['zcool.com.cn'] start_urls = ['https://www.zcool.com.cn/home?p=1#tab_anchor'] # 第一页的url def parse(self, response): global count count += 1 for div in divList: # ...xxx... yield item next_url = 'https://www.kuaikanmanhua.com/tag/0?state=1&sort=1&page={}'.format(count) yield scrapy.Request(next_url)这两种方法都是在实际案例中使用的。
7.5 数据存储
数据存储是在pipline.py中完成的,代码如下:
from itemadapter import ItemAdapter import csv class ZcoolPipeline: def __init__(self): self.f = open('Zcool.csv','w',encoding='utf-8',newline='') # line1 self.file_name = ['imgLink', 'title','types','vistor','comment','likes'] # line2 self.writer = csv.DictWriter(self.f, fieldnames=self.file_name) # line3 self.writer.writeheader() # line4 def process_item(self, item, spider): self.writer.writerow(dict(item)) # line5 print(item) return item # line6 def close_spider(self,spider): self.f.close()说明:
- line1:打开文件,进入第三种模式为write 写入csv数据 去掉空行generated by
- line2:设置文件第一行的字段名。注意一定要和传给spider的字典key的名字一样
- line3:指定写入文件的方式为写入csv字典,参数1 如果要指定具体文件,参数2是指定的字段名
- 第 4 行:写入第一个字段名行,因为只需要写入一次,所以文件放在 __init__ 中
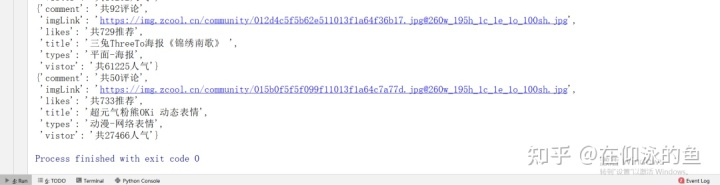
- 第 5 行:写入蜘蛛出售的具体名称数值。请注意,spider 文件中的yield 项是由该类创建的实例对象。当我们写入数据的时候,我们写入的是一个字典,所以我们需要在这里进行转换。?直接运行start.py文件:得到如下结果:
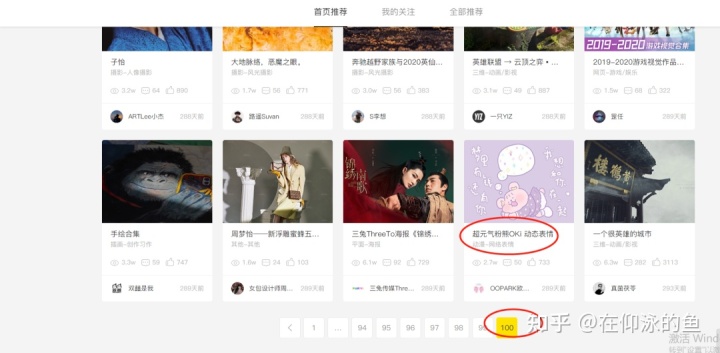
 对应页面:
对应页面:
 打开csv word文件如下:使用Open Notepad++)
打开csv word文件如下:使用Open Notepad++)
没问题,收藏数据完整。7.7。总结
入门案例需要细心留意,主要是巩固基础知识,为进阶教育做好准备。
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。






作者文章
- 用小程序学英语到底有没有用?适合哪些人?避坑指南加靠谱用法有吗? 2周前 (05-22)
- 2024-2025做通用和本地生活小程序没人看没人下单怎么办?试试这6个小成本留客转化型技巧 2周前 (05-22)
- 做小程序英文翻译避不开哪些坑?怎么翻才能吸引海外用户留存? 2周前 (05-21)
- Vue3 Composition API watch开启deep后踩过哪些坑?如何高效用它处理深层数据监听? 3周前 (05-19)
- Vue3中watch监听props时,deep:true到底该不该随便开? 3周前 (05-19)