 code前端网
code前端网Tensorflow 学习笔记:模型构建和训练
1。 Python函数装饰器
装饰器:改变其他函数功能的函数
def hello(a_func()):
def first():
print("hello,")
a_func()
print("my friend!")
return first
def name():
print("Penny,")
name = hello(name)可以创建嵌套函数
将函数作为参数返回时间:
- 如果在函数名后面放一个函数,将会函数将会被执行
- 如果你不在函数名后面加上括号,那么函数名可以被传递并赋值给其他变量而不是执行函数
@:生成一个简短的方法装饰函数 [1]
@hello
def name():
print("Penny,")2. 模型和层
在 TensorFlow 中,建议使用 Keras (tf.keras) 在 high❝ 模型上构建。简单、快速、灵活的-级神经网络API。它现已正式内置并受 TensorFlow 完全支持。 [2]
模型和层是Keras中的两个重要概念:
- 层:封装不同的计算过程和变量
- 模型:组织和连接不同的层,并将它们封装在一个中使用 y_pred = model(x) 的形式调用模型。 tf.keras.layers 内置了大量深度学习中常用的预定义层
Keras 模型以类的形式呈现,通过继承 tf.keras.Model 类来定义模型;继承类时,需要重写 _init_() 和 call(input) 方法,也可以添加自己的方法 [2]
class MyModel(tf.keras.Model): def __init__(self): super().__init__() # Python 2 下使用 super(MyModel, self).__init__() # 此处添加初始化代码(包含 call 方法中会用到的层),例如 # layer1 = tf.keras.layers.BuiltInLayer(...) # layer2 = MyCustomLayer(...) def call(self, input): # 此处添加模型调用的代码(处理输入并返回输出),例如 # x = layer1(input) # output = layer2(x) return output # 还可以添加自定义的方法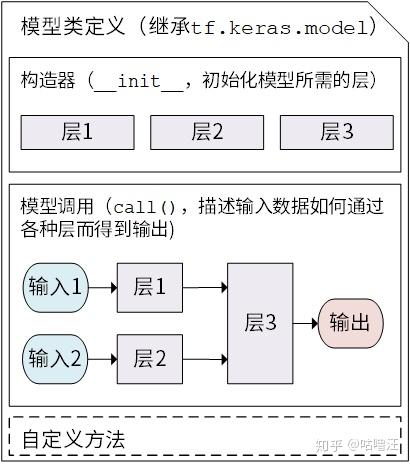
Kera 的模型类定义图 - https://tf.wiki /zh_hans/basic/models.html
继承tf.keras.Model后,可以调用父类的方法和属性。模型中的所有变量都可以直接通过 model.variables 获取
class Linear(tf.keras.Model): # 建立了一个继承了 tf.keras.Model 的模型类 Linear def __init__(self): super().__init__() self.dense = tf.keras.layers.Dense( # 实例化了一个 全连接层 units=1, # 输出张量的维度 activation=None, # 激活函数,默认为无激活函数 a(x) = x kernel_initializer=tf.zeros_initializer(), # 权重矩阵kernel的初始化器,默认为tf.glorot_uniform_initializer bias_initializer=tf.zeros_initializer() # 偏置向量bias的初始化器,默认为tf.glorot_uniform_initializer ) def call(self, input): # 对 全连接层 进行调用,实现了线性变换的计算 output = self.dense(input) return output model = Linear() optimizer = tf.keras.optimizers.SGD(learning_rate=0.01) for i in range(100): with tf.GradientTape() as tape: y_pred = model(X) # 调用模型 y_pred = model(X) 而不是显式写出 y_pred = a * X + b loss = tf.reduce_mean(tf.square(y_pred - y)) grads = tape.gradient(loss, model.variables) # 使用 model.variables 这一属性直接获得模型中的所有变量 optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables)) print(model.variables)可以看到,不需要显式声明 a 和 b,也不需要声明线性变换 y_pred=a*X+b
- 全连接tf.keras.layers.Dense:对输入矩阵进行线性变换+激活函数操作
- 给定输入张量input=[batch_size,input_dim],首先进行tf.matmul(input,kernel)+bias的线性变换,然后通过激活函数给出线性变换后的张量的每个元素,得到二维张量[batch_size,units]
- 常用的激活函数有tf.nn.relu、tf.nn.tanh、tf. nn.sigmoid
- 如果不指定激活函数,则是纯线性变换
- use_bias:无论是否添加偏置向量,默认都是True
- tf.zeros_initializer表示一切初始化变量为0 kernel=[input_dim,units] 和bias=[units] 是两个可学习变量
三。示例:多层感知器 (MLP)
1。使用
tf.keras.datasets检索数据集并预处理
2. 使用tf.keras.Model和 ⸝ 3. 构建该模型。构建模型训练过程中,使用tf.keras.losses计算损失函数,并使用tf.keras.optimizermodel使用构建模型评估流程tf.keras.metrics计算评估指标 [2](续)
参考
- ^Python functionob.com/wrunc func-decorators.html
- ^abcTensorFlow 模型建立和训练 https://tf.wiki/zh_hans/basic/models.html
参考
- ^Python 函数装饰器 https://www.runoob。 com/w3cnote/python-func-decorators.html
- ^abcTensorFlow modelhans.html/模型建立与训练
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。




