 code前端网
code前端网Golang goroutine 是如何实现的?
goroutine 实现:
让我们看看调度的演变,从进程到线程再到协程。它实际上是一个不断共享、不断降低变革成本的过程。 go实现的协程是一个栈协程。使用 go 协程基本上与使用线程类似。很多人会问,协程到底是什么?用户态的调度很奇怪也很抽象,到底是什么呢?
我觉得如果想要理解调度就需要理解两个概念:运行和阻塞。尤其是在协程中,正确理解这两个概念并不容易。我们在理解概念的时候,往往会代入自己的感受,感觉线程或者协程的运行就像我们处理事情的时候一样。 ,阻塞线程或协程意味着我们必须等待其他人做事情。那我们就在这里等吧。如果别人已经做到了,那我们就继续当前的事情。
其实主要目标是错误的。正确的理解应该是我们把事物当作CPU来处理,而不是当作线程或者协程来处理。如果我正在编写一项服务并发现依赖于其他服务的功能尚未准备好,我将推迟编写该服务。我点了企业微信,去和产品沟通一些问题。和产品沟通了一段时间后,检查发现依赖的函数是别人提交的。然后我最小化企业微信,切换到IDE继续打字。服务A。
对操作系统有一点了解。我知道Linux下的线程其实就是task_struct结构。线程并不是真正运行的实体。线程仅代表执行流程及其状态。驱动程序进程的实际运行仍在继续。其实就是CPU。时钟驱动的处理器根据PC寄存器从程序中检索指令和操作数,从RAM中检索数据,进行计算、处理、跳转并驱动执行流程向前推进。 CPU不重视处理。无论是线程还是协程,只要设置PC寄存器,设置堆栈指针等即可。 (这些称为上下文),那么 CPU 就可以愉快地运行该线程或协程。
线程运行真正开始了。阻塞实际上就是将其从调度队列中移除,不再调度该执行流的执行。当其他执行线程满足其条件时,从调度队列中删除的执行线程将返回到调度队列中。协程也是如此。协程实际上是一种数据结构,记录了要执行什么函数以及在哪里执行。
go 实现了用户态调度,因此 go 必须有一个表示协程执行流程的结构以及保存和恢复上下文的函数。开始排队。了解阻塞的真正含义更容易理解为什么 Go 锁和通道不会阻塞线程。
至于无线程网络阻塞的同步执行的流程效果,我们下次想象一下。
程序结构及切换功能我们去func的时候一般会这样写go func1(arg1 type1,arg2 type2){....}(a1,a2)
协程代表执行的流程。一个执行流程有需要执行的函数(对应上面的func1)、函数输入参数(a1,a2)和当前的执行流程。状态和进度(对应PC寄存器和CPU SP寄存器),当然还必须有一个地方来存储状态以恢复执行流程。
协程真正代表的是运行时结构。每个go函数都会被编译成一个runtime.newproc函数,最后一个runtime.g对象会被放入调度队列中。上面函数func1的指针被设置在startfunc运行时字段.g中。 newproc函数中参数被复制到堆栈上,sched用于存储协程。切换时的计算机位置和托盘位置。
关闭和恢复协程时,需要保存上下文和恢复上下文。这些是通过以下两个汇编函数实现的。以上可以实现协程执行以及切换刷新的流程。 (下图中的结构和功能已经简化)
GM模型和GPM模型
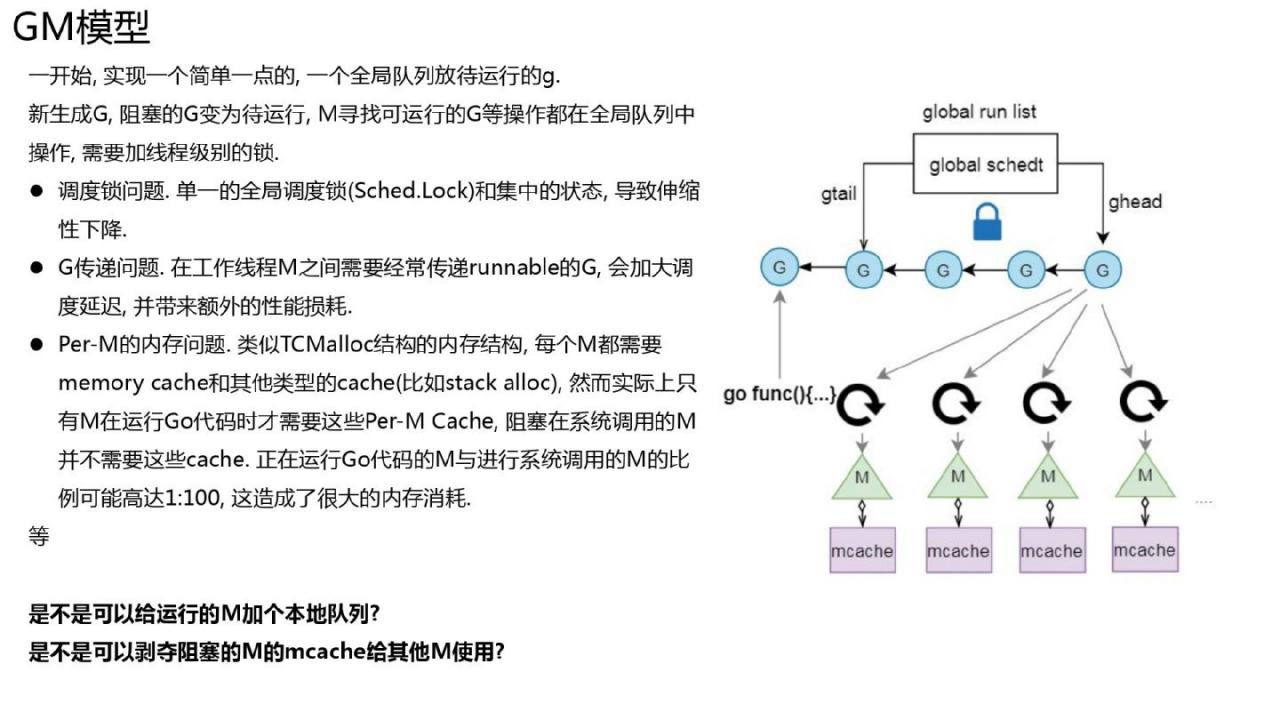
这种形式的执行流程中协程应该执行到哪里?
Go1.0中:
- 调度队列调度是全局的,并且在队列中进行操作,它们必须竞争同一个锁,导致可扩展性较差。
- 新生成的协程也会被放置到全局。该队列很可能由其他m(可以看作底层线程的表示)管理,并且内存亲和性不好。当前协程A会创建一个新的协程B,然后协程A很可能会终止或者阻塞,所以m会直接执行协程B,内存亲和性会好很多。
- 由于mcache与m绑定,在某些应用中(比如文件操作或者其他可能会阻塞线程的系统调用),m的数量可能会远远超过活跃的m数量,从而造成比较大的内存浪费。
是否可以分配一个队列 m 并使用阻塞的 mcache m 让 m 执行 go 代码? Go 1.1 及之后的版本就是这么做的。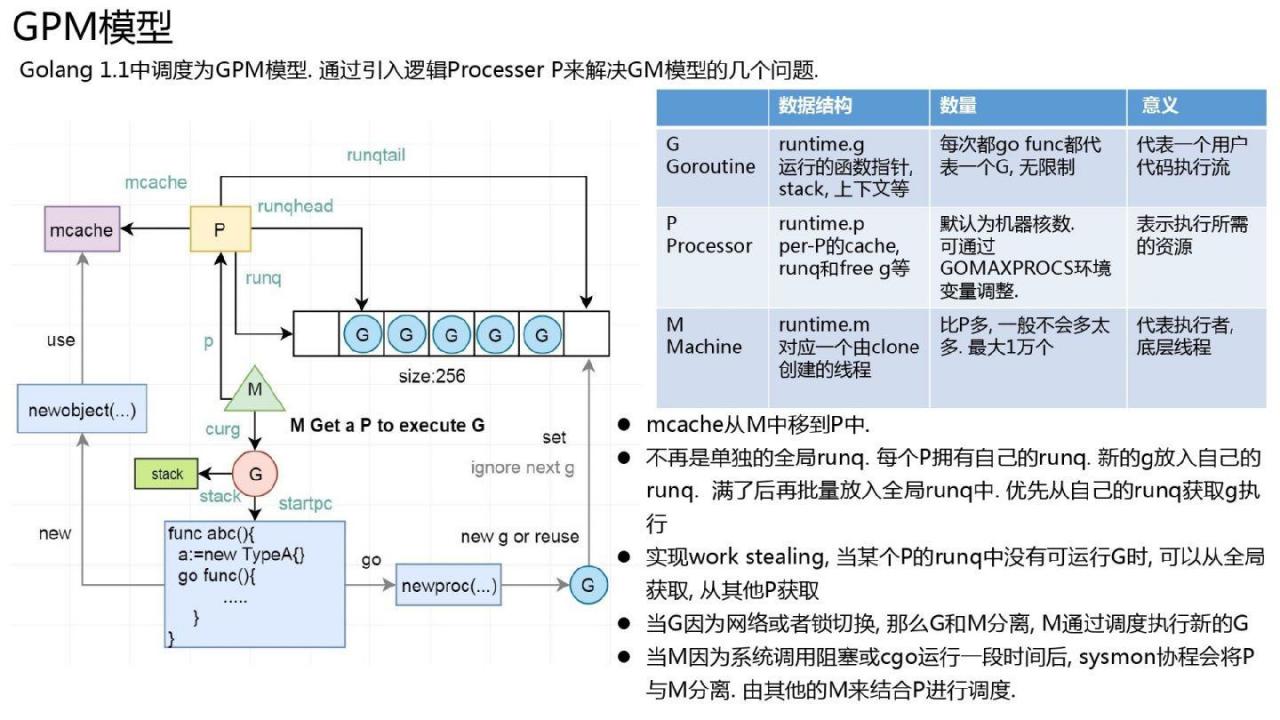
1.1 中,调度模型改为 GPM 模型,并引入了逻辑进程的概念,逻辑进程代表运行 Go 代码所需的资源,也是 Go 语言中的最大并行度。去代码执行。
很多人可能不知道如何理解这个术语。 P包括几个点、队列和mcache,选择P的数量.
首先,为什么全局队列会分裂,为什么mcache跟随P,GM模型页面上已经解释得很清楚了。那么为什么P的数量默认为CPU核心的数量:Go试图提高性能,那么如何才能在n核机器上最大限度地利用CPU能力呢?当然,为CPU提供动力的n个线程是并行运行的,也就是说,代码总是在所有核心上运行,它不需要CPU,也不需要分配中间级内存。只有并行运行的 go 代码才需要这些资源。这意味着如果有n个go协程同时并行执行,就可以最大程度地利用CPU。此时所需的P数量即为CPU核心数。 (注意并行和并发的区别)
协程状态和流程
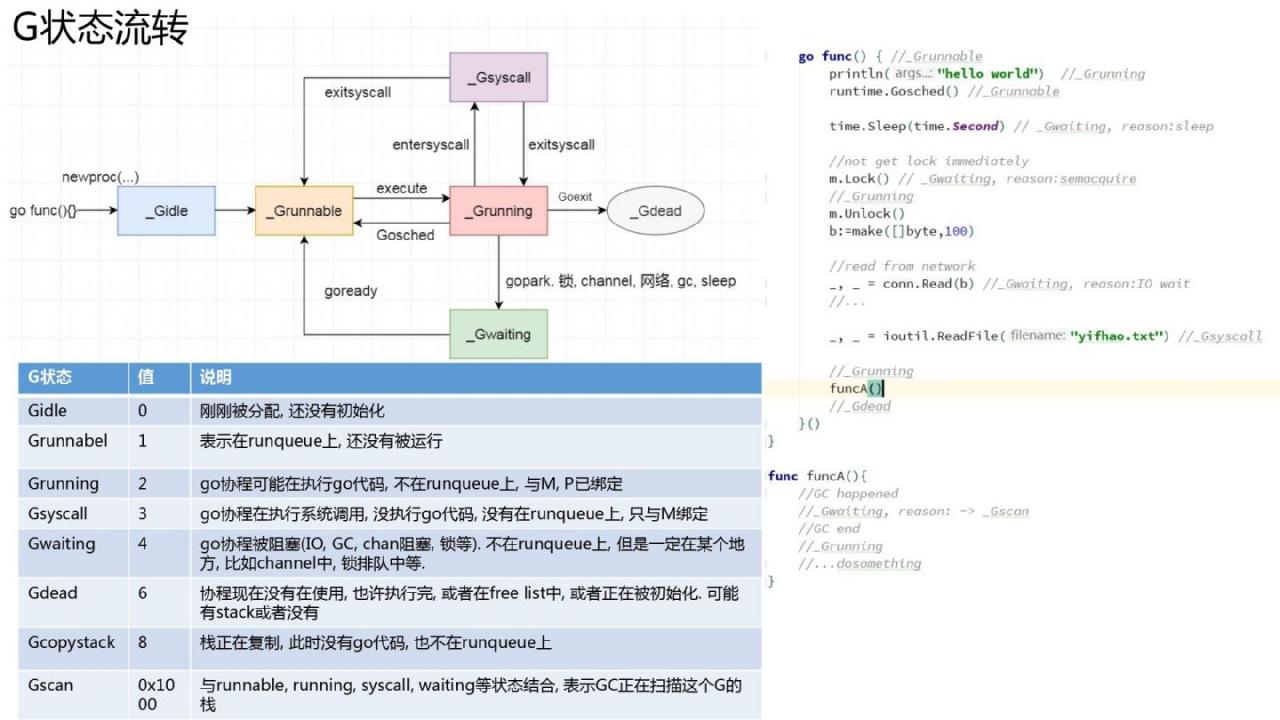
协程状态其实和线程状态类似。状态转换及状态转换时序如图所示。仍然值得注意的是:协程只是一个执行流程,而不是一个运行实体。
调度
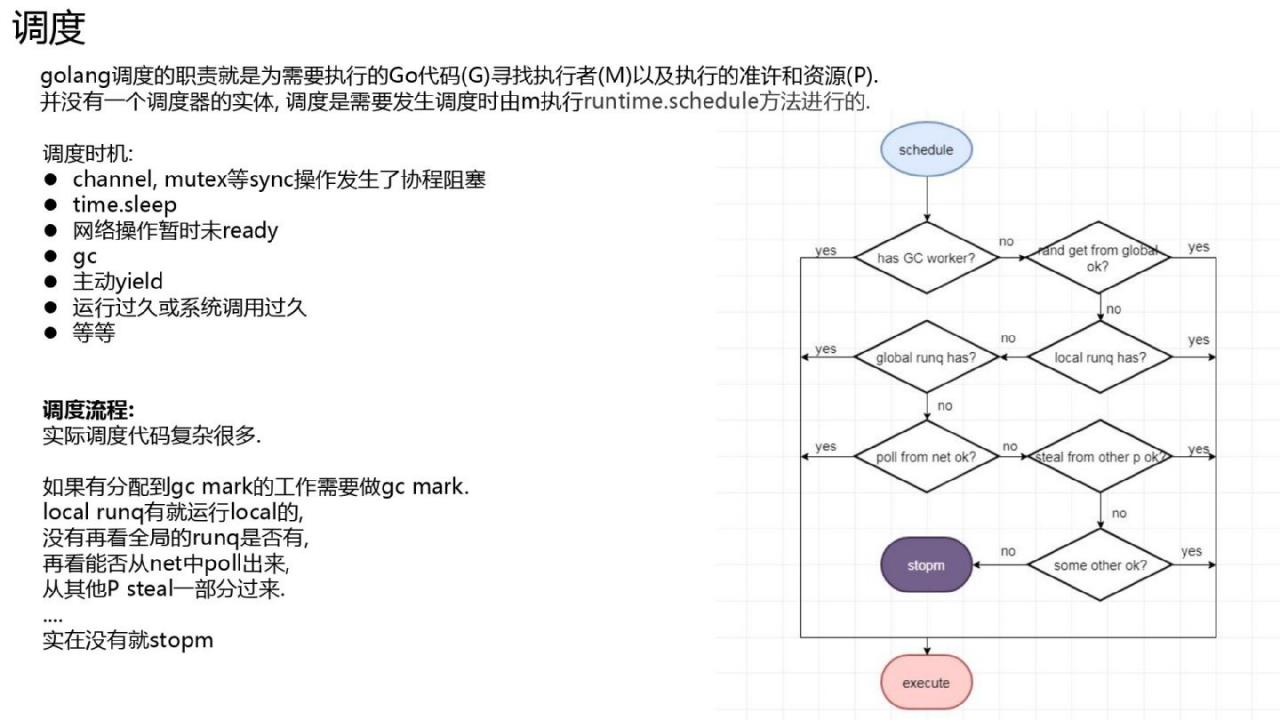
否 启动调度的调度程序实体。当协程或者新生成的m关闭时,运行时go会从stw重新启动等,这时需要进行规划。 Go通过线程(m)的调度是通过执行runtime.schedule函数来完成的。
sysmon 协程
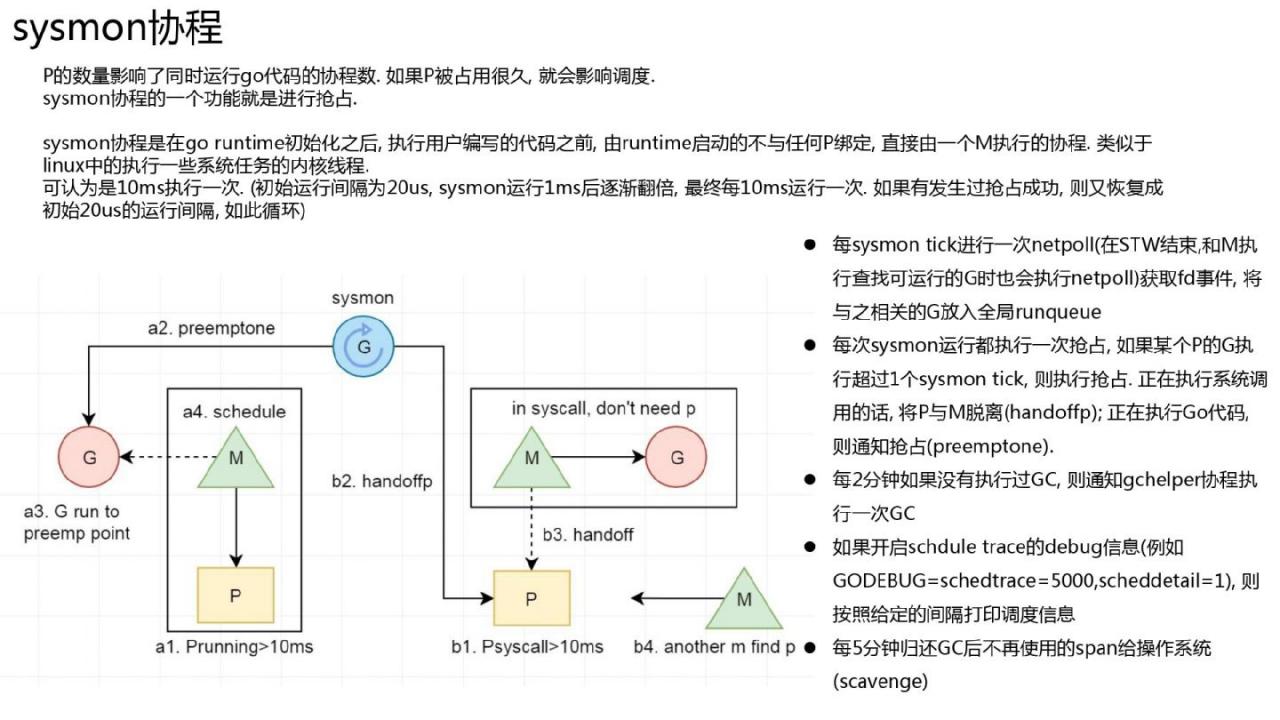
在 Linux 内核中,有几个线程执行定时任务,比如定期写掉脏页的 pdflush、定期刷新内存的 kswapd0、以及每个 CPU 都有一个迁移线程负责负载均衡等go运行时也有一个类似的协程,sysmon。它的功能很多:定期从netpoll中检索准备好的协程、抢占、调度GC、打印调度信息、返回内存等定时任务。
合作抢占

go 目前(1.12)未实现非合作抢占。基本流程是sysmon协程指示某个协程运行时间过长,需要关闭。协程开启 当函数启动时,将检查堆栈标记,然后进行切换。
同步执行流程而不阻塞线程的网络实现
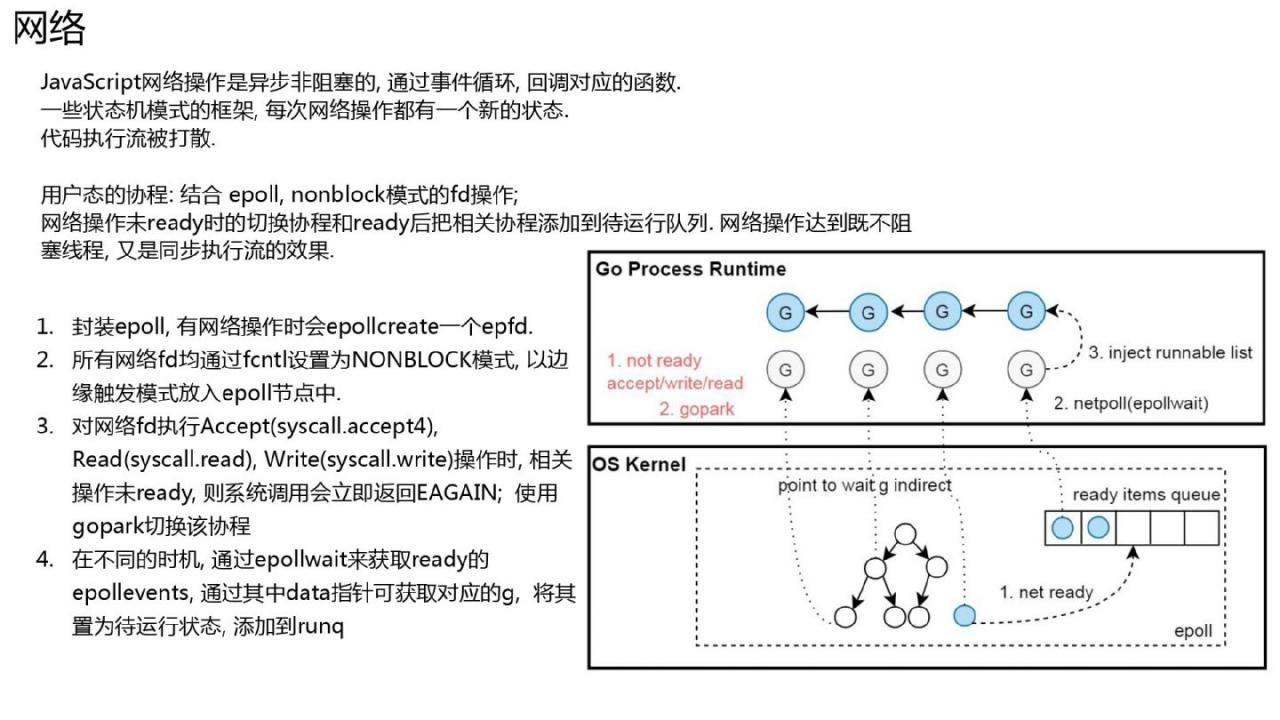
go 后台写最方便的地方就是可以同步操作网络,但是网络操作不会阻塞线程。主要结合了fd、epoll和协程的非阻塞切换和恢复。 Linux提供了非阻塞的fd网络模式。当对未就绪的非阻塞fd执行网络操作时,Linux内核不会阻塞线程,直接返回EAGAIN。此时协程的状态被设置为等待,然后m调度更多的协程。
go初始化网络fd时,会使用epollctl将这个fd添加到全局epoll节点中。同时,polldesc指针也会被包含在epoll中。
func netpollopen(fd uintptr, pd *pollDesc) int32 {
var ev epollevent
ev.events = _EPOLLIN | _EPOLLOUT | _EPOLLRDHUP | _EPOLLET
*(**pollDesc)(unsafe.Pointer(&ev.data)) = pd
return -epollctl(epfd, _EPOLL_CTL_ADD, int32(fd), &ev)
}
在sysmon系统中,调度函数中,当netpoll调用epollwait系统调用从epoll中获取就绪的网络事件时,中间情况下会触发world。任何网络事件都可以通过之前传递的 polldesc 来检索被阻塞在其上的协程,将协程恢复为可运行的调度程序。类似于 tcmalloc。特点:使用一小块持久内存页来分配某些不同大小的内存需求。例如,保留一定的连续8KB来分配17-24字节,以减少内存碎片。线程有一些可用于无锁分配的缓冲区。
同时,Go 使用 GC 页面后回收的内存不会立即返回给操作系统,而是会延迟返回以满足未来的内存需求。
内存空间结构
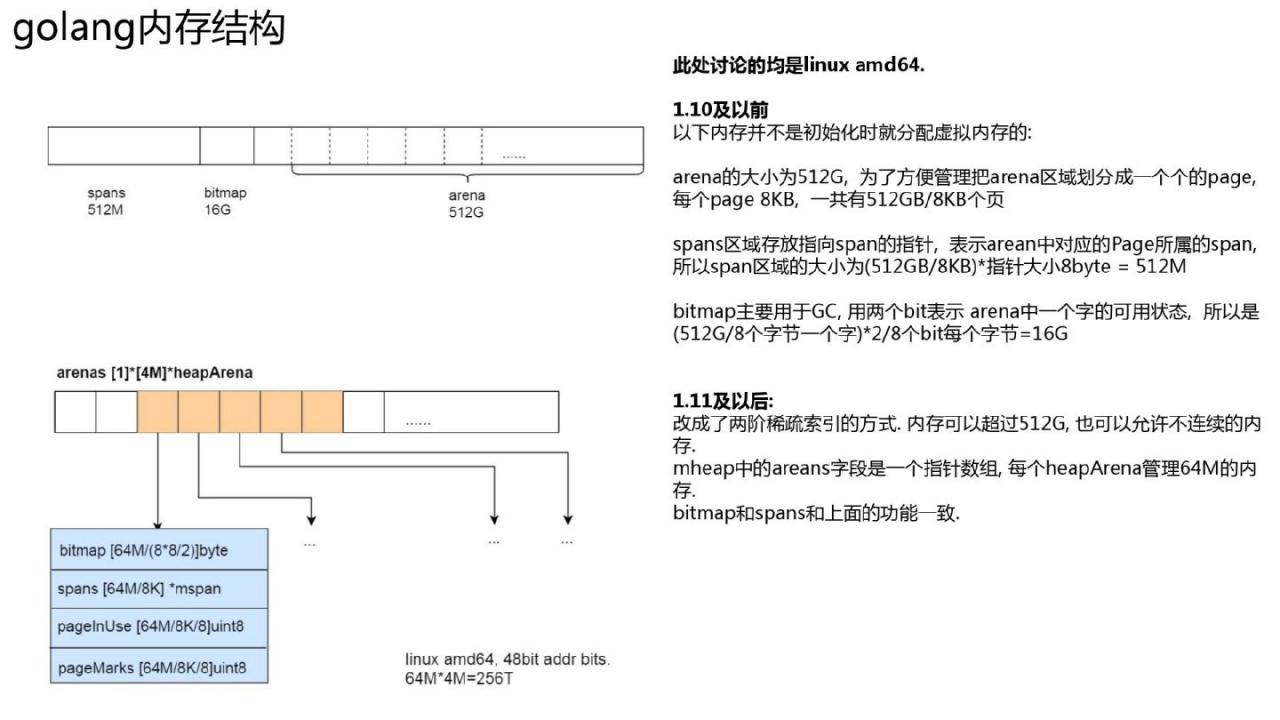
在1.10之前,go堆地址空间是线性连续扩展的,比如在1.10(linux amd64)中,最大可以扩展到512GB。因为go会通过gc时得到的指针的地址来判断是否在go堆中,并找到其对应的范围。判断机制要求gc堆是连续的。 。但不断扩张就存在一个问题。 cgo 中的代码(尤其是在 32 位系统上)可能会占用将来用于堆的内存。这样,当扩展go堆时,mmap就会出现不相交的地址,从而导致运行时抛出异常。
在1.11中,使用稀疏索引方法来管理总内存。内存可以超过512G,扩展内存空间时也可以允许不连续。全局mheap结构中有一个二阶arena数组。在 linux amd64 上,第一层只有一个插槽。第二级有4M个slot,每个slot指向一个heapArena结构体,每个heapArena结构体可以管理64M内存,所以在新版本中,go可以管理4M*64M=256TB内存,即当前的48bit内存64 位机器。地址总线共有 256 TB 内存。
Span 机制
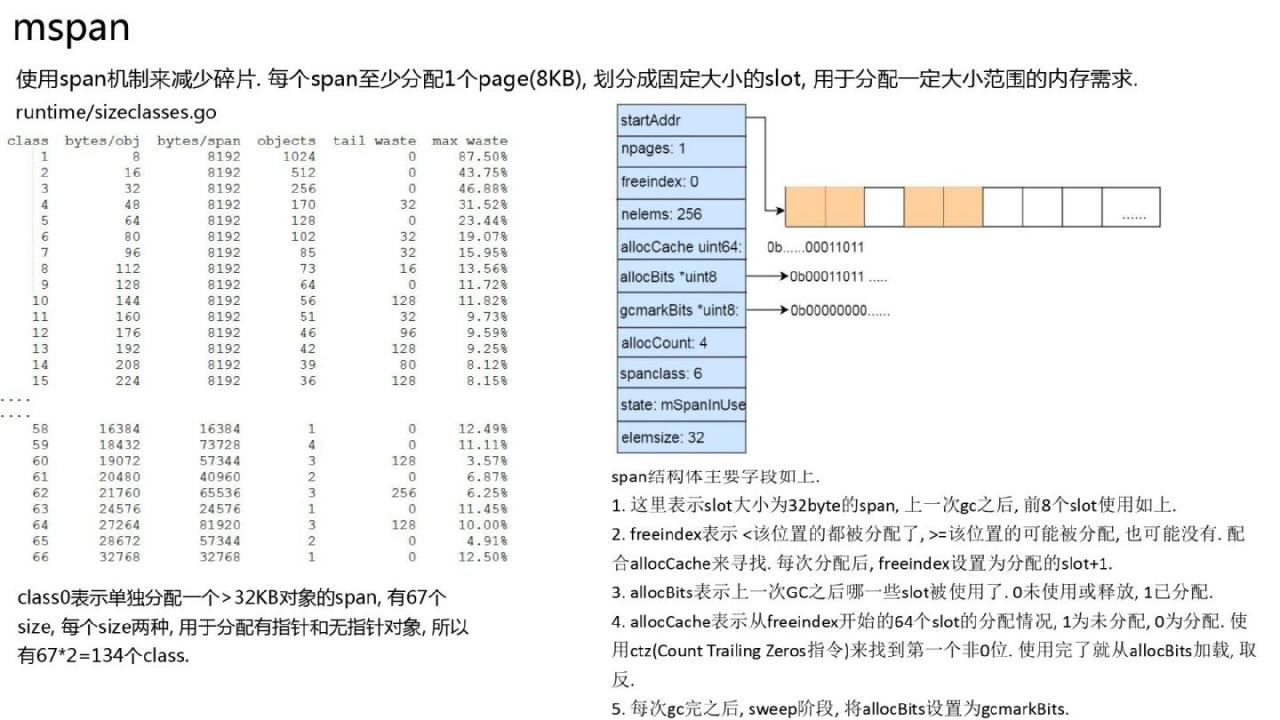
前面提到过,Go 的内存分配与 tcmalloc 类似,采用了 Span 机制来减少内存碎片。每个盘区管理 8 KB 整数倍的内存,用于分配特定盘区。内存要求。
内存分配全景
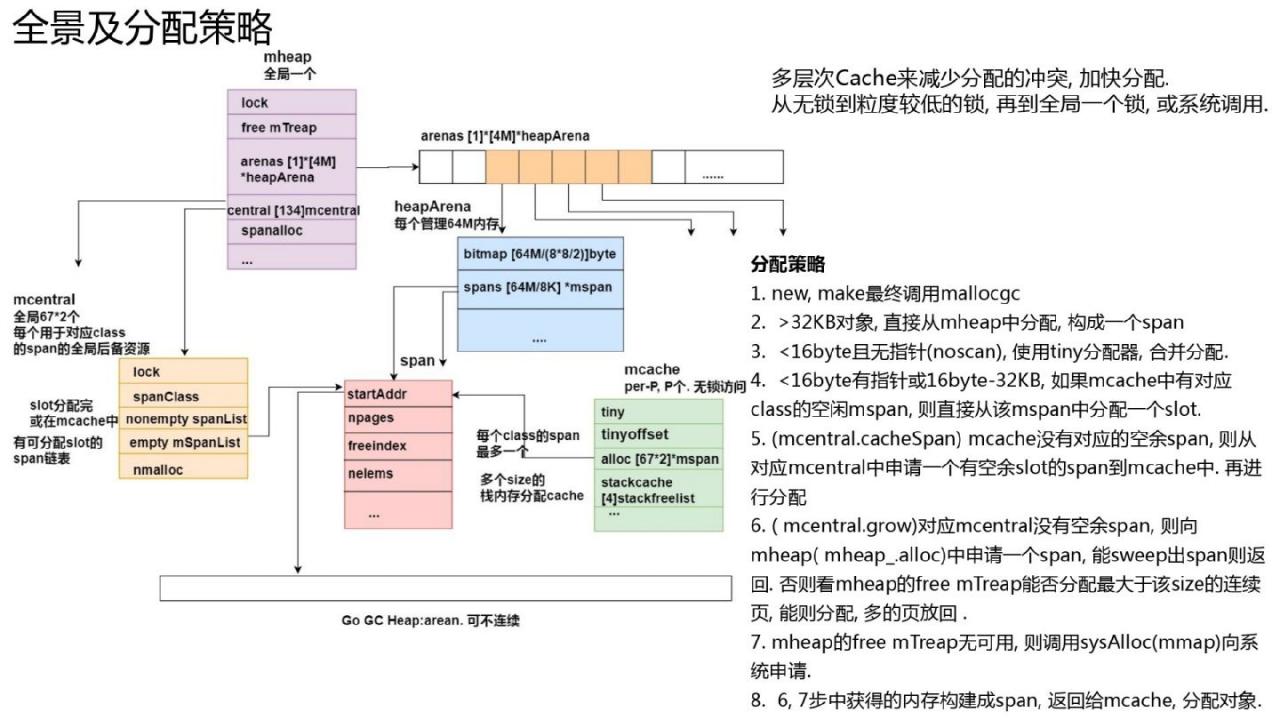
多级分配缓存,每个P上有一个mcache,mcache每个大小最多缓存一个extent,用于非锁定分配。每种大小的全局边距都有mcentral,锁粒度比全局堆小很多。每个mcentral可以认为是每个大小范围的全局备份缓冲区。
gc完成后,P中的所有范围都会被刷新到mcentral中,用于清理然后分配。当P需要span时,从相应大小的mcentral中获取。如果获取失败,则会在全局堆上递增。
一些特殊的分配器

对于非常小的对象,Go做了一个优化,将小对象连接起来,通过移动指针来分配它们。堆栈内存有 stackcache 分配,并且有多个级别的分配。同时,堆栈有几种不同的大小。用于分配堆栈的内存也在mspan管理的go gc堆中,但是这个extent的状态与用于分配对象的mspan的状态不同。就是mSpanManual。
我们可以思考一下这个问题。 Go对象在go gc堆中分配,并管理mcache、mspan和mcentral等结构。那么 mcache、mspan 和 mcentral 等托管和分配结构在哪里?他们肯定无法处理自己。它们都分配有一个特殊的分配fixalloc,并且每种类型都有一个fixalloc。总体原理是通过mmap从进程空间获取一小块内存(大约一百kB),然后用它来分配这个固定大小的结构。
复杂的内存分配

GC
Golang GC简介

GC简介

GC并不是什么新鲜事,是Java语言让GC大放异彩 Golang开发GC
go func1(arg1 type1,arg2 type2){....}(a1,a2)
Go1.0中:
func netpollopen(fd uintptr, pd *pollDesc) int32 {
var ev epollevent
ev.events = _EPOLLIN | _EPOLLOUT | _EPOLLRDHUP | _EPOLLET
*(**pollDesc)(unsafe.Pointer(&ev.data)) = pd
return -epollctl(epfd, _EPOLL_CTL_ADD, int32(fd), &ev)
}
以上是一些比较重要的版本。左图是根据Twitter工程师的数据绘制的(堆得挺大的),从1.4时几百ms的停顿到1.8时不到1ms。正确的图片是我在线服务测试的结果之一(Go 1.11内置)是一个突发下载数据的服务,大约3000qps,在该服务上发起的RPC调用大约2w/s。可以看到,大多数情况下GC停顿时间都小于1ms,偶尔也不止一点点。
总体来说,golang gc 使用起来非常方便,几乎不需要你操心。
三色品牌
go采用同时三色清洗方式。图片展示了一个简单的原理。有几个问题需要考虑:
- 发生碰撞时标记的物体会丢失吗?
- 物体的三色状态存储在哪里?
- 如何根据对象Object找到它的引用?
写屏障
GC 最基本的是正确性:不要忽略标记的对象并且程序中仍在使用的所有对象都已被删除,然后程序有问题。一些漂浮垃圾是允许的。
并发的情况下,如果没有措施保护,会出现什么问题?
看左边的代码和图表。在步骤2中标记对象A后,如果A不引用该对象,则A变成黑色对象。步骤3,mutator(程序)运行,将对象C从B转移到A。步骤4,GC继续标记扫描B。此时B已经没有对象的引用,变成黑色对象。我们发现对象C缺少标记。
如何解决这个问题? Go 使用写屏障。这里的写屏障指的是编译器生成的一小段代码。 gc期间指针操作之前执行的一小段代码 该代码与CPU中维护内存一致性的写屏障不同。所以写屏障发生后,在步骤3中当A.obj=C时,将C添加到写屏障buf中。最终将被扫描。 ![]()
这里是写屏障生成的具体代码的体验。我们可以看到,当写入指针槽时,会检查写屏障是否打开。如果打开,它会跳到写屏障功能并添加写屏障 buf。逻辑。 Dijkstr 1.8 中的类型障碍写屏障已更改为混合写屏障,可将 GC 暂停时间减少到 1 毫秒以下。
三色状态
没有任何集合可以将不同状态的对象存储到相应的集合中。这只是一个逻辑意义。
扫描和元信息
gc获取一个指针,将这个指针所指向的对象引用的所有子对象添加到扫描队列中?另外,go还允许内部指针,这似乎问题比较多。我们来分析一下。如果你想知道一个对象所引用的子对象,从对象的开头到对象的结尾,只要在扫描队列中放入一个指向该对象内存的指针即可。然后我们需要知道这个物体有多大,它从哪里开始,到哪里结束?同时,我们需要知道内存中的8个字节的指针在哪里,常规数据在哪里。
首先,Go对象是通过mspan来管理的。如果我们知道该对象属于哪个范围,我们就会知道该对象有多大以及从哪里开始。 ,结束的地方。我们之前讨论过区域的结构。可以给指针加上一些偏移量来知道它属于64M堆区的哪个块。然后找到64M的余数,与spans数组连接起来,就可以知道它属于哪个mspan了。
结合heapArean位图和heapArean中每8个字节的偏移量,就可以知道一个对象的每8个字节是指针还是普通数据(这里的位图是根据分配对象时的类型信息设置的) )是的,类型信息来自生成的编译器)
GC过程
1.5和1.12的GC过程大致相同。上图是golang官方ppt中的图片,下图是我根据1.12源码绘制的。从最新开始可能会有数百ms的gc暂停,直到稳定在1ms以下。在此期间,GC做了很多改进。右边是我根据官方问题整理的一些重要调整。 1.6中的分布式检测,1.7中的堆栈收缩在并发扫描阶段,1.8混合写屏障,1.12更改了标签终止检测算法,mcache刷新删除了标签终止等。
Golang GC Pacer
大家对并发GC除了如何保证不泄漏指针之外还有疑问。此外,你可能还想知道并发GC如何保证能跟上应用程序的分配速度?会不会分配太快GC根本跟不上然后OOM?
就是这样这是 Golang GC Pacer 功能。
Go 的 GC 是比例 GC。下一次GC结束时堆的大小与上一次GC剩余堆的大小成正比。它由 GOGC 控制。默认值为 100,即 2 倍比率。 200是3倍,以此类推。
如果上一次 GC 完成后,存活对象数为 10 亿,默认 GOGC 值为 100,那么下一次 GC 将在接近但小于 20 亿(例如 19 亿)时开始,并且当达到2000M时会尝试增加桩尺寸。两者之间存在一定的差异。计算待扫描对象的大小(根据历史数据计算)与可分配储备的比率。应用程序根据这个比例分配内存并执行辅助GC。如果应用程序分配太快,导致信用不足,就会被阻塞,直到后台标签赶上。该比例将由GC不断调整。
GC结束后,会根据本次GC的情况计算负载。反馈计算,计算启动下一次GC的阈值。
如何保证GC按时完成? GC完成后,所有的mspan都必须进行扫描,就像GC比率一样,在GC结束和下一次GC开始之间有一定的时间。堆分配保留将取决于需要擦除多少内存来计算分配内存时需要擦除的盘区数量的比率。 ![]()
练习与总结
遵守时间表
遵守时间表,增加一些要求。我们可以看到,虽然有1000个连接,但是go只用很少的线程就可以处理它们,说明go网络确实在管理epoll。 runqueue 表示全局队列中要运行的协程数量,后面的 Number 表示每个 P 上要运行的协程数量。可以看到,要处理的作业数量并没有增加,说明可以容纳很多请求。
同时可以看到,有时不同P上的任务可能会不平衡,但过了一段时间,任务又平衡了,这说明go work偷窃是有效的。
注意GC
有些数据的含义在分享时没有解释,但网上有解释,几乎没有解释可以完全正确。让我在这里分解一下。
其实,一般来说,重点关注堆大小和两个stw的wall time。
gc 8913 (8913.gc) @2163,341s (在8913.程序开始时间) 2163s) 1%(所有 gc 工作消耗的历史累积 CPU 分数,因此该数据实际上并没有多大意义)0.13(第一个 stw wall time)+ 14(并发标记 wall time)+ 0.20(第二个 stw wall time))ms 小时,1.1 (第一个 stw 消耗的 CPU 时间)+ 21(用户程序辅助扫描消耗的 CPU 时间)/22(分配给标签的 P 消耗的 CPU 时间)/0(用于标签的空闲 CPU 时间)+ 1 .6ms(第二个 stw 处理器时间) cpu, 147 (gc 开始时的堆大小) -> 149 (gc 结束时的堆大小) -> 75MB (gc 结束时的生存堆大小), 151MB 目标 (预计堆大小终止此 gc) )、8P(8P)。
优化
个人建议,没事的时候不要总想着优化,做好凝乳就好。 ![]()
当然,还有一些方法可以优化。
一点练习
我们在模板中集成了pprof开放,自动选择端口,并集成了gops工具,方便查询运行时信息。同时,可以直接点击浏览器,生成火焰图。 pprof图非常方便,不需要用户关心。
一些排查思路
有趣的排查
负载和依赖服务都正常,CPU占用率不高,请求也不多,只是超时很多。 ![]()
该服务在线打印调试日志,因为早期的服务模板开启了 gctrace,并且框架将 stdout 重定向到文件。在 gctrace 输出上,它最初进入控制台并到达文件输出,但磁盘无法跟上,导致 gctrace 日志挂起。
我来纠正一下ppt中的内容。不是其他协程因为gc没有完成而不能运行,而是后续的gc不能运行,基本上导致stw。
打印gc跟踪日志时,世界开始了,他们可以运行其他协程运行。但是在打印gctrace日志时,打开gc所需的锁仍然被保留,所以打印了gc跟踪日志。没有完成,而且gc很频繁,比如每0.1秒一次。这将导致另一个 gc 运行。一开始就获取不到锁,每一个进入gc检查的p都被阻塞,这实际上导致了stw。
个人小总结运行时
并行,纵向多级,横向多类,缓存,缓存和平衡。
参考文档
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。






作者文章
- 用小程序学英语到底有没有用?适合哪些人?避坑指南加靠谱用法有吗? 3周前 (05-22)
- 2024-2025做通用和本地生活小程序没人看没人下单怎么办?试试这6个小成本留客转化型技巧 3周前 (05-22)
- 做小程序英文翻译避不开哪些坑?怎么翻才能吸引海外用户留存? 4周前 (05-21)
- Vue3 Composition API watch开启deep后踩过哪些坑?如何高效用它处理深层数据监听? 4周前 (05-19)
- Vue3中watch监听props时,deep:true到底该不该随便开? 4周前 (05-19)