1.锁?
1.1 什么是锁?计算机锁通常用于管理对共享资源的访问。比如我们Java同学都知道的Lock、synchronized等就是我们常见的锁。当然,数据库中也有锁来控制对资源的访问,这也是数据库和文件系统的区别之一。 1.2 为什么需要了解文件锁?
总的来说,对于简单的开发者来说,使用数据库时了解DQL(选择)、DML(插入、更新、删除)就足够了。
小明是一名Java开发者工程师,刚刚毕业,在一家互联网公司工作。它的正常功能是完成PM的要求。当然,在做需求的同时,他也离不开spring框架、springmvc、mybatis,所以基本上我还是手写SQL。如果遇到更复杂的SQL,我会上网百度。对于一些更重要的任务,比如谈判,小明会使用spring事务来管理数据交换。由于数据量比较小,目前不包含分布式事务。
小明这几个月过得还不错。有一天,小明接到一个请求。卖家有一个确认项目,称为折扣确认项目。您可以配置买一送一、买一送二等。当然这些配置是批量传到后端的,所以有问题。每条规则无论是删除、添加还是修改都必须匹配,这使得后端逻辑更加繁琐。聪明的小明想了一个办法,直接抹掉它。供应商设置并将其全部添加。小明立即改革并获得成功。
开始上网没有问题,但是日志中经常出现mysql-insert-deadlock异常。由于小明经验不多,第一次遇到这样的问题,于是他请教了组里经验丰富的司机大洪。大洪发现问题后,查看了自己的代码,发出了几条命令。写完日志,立马看到问题,告诉小明:这是因为删除的时候加了间隙锁,但是间隙锁是互相兼容的,但是插入新数据的时候,就会被间隙锁阻塞是意向锁。 。 ,导致双方都没有资源赖以生存,造成停电。小明听了这话,似乎明白了。由于大洪还有很多事情要做,总不好去打扰大洪,所以他决定先下去自己想一想。小明下班的时候,想起了大洪说过的话,什么是间隙锁,什么是插入意向锁。作为开发人员,你不应该只为数据库编写SQL,否则你将无法解决复杂的问题。想通了这一点,小明就走上了学习MySQL锁的不归路。
2.InnoDB
2.1mysql架构
小明并没有急着打开这个知识。他首先了解了Mysql的架构: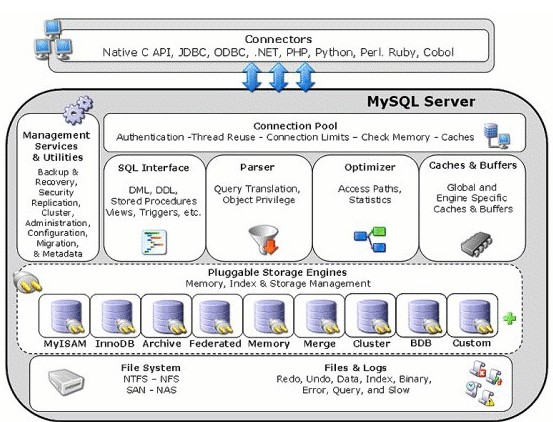 可以看到Mysql由连接池组件、管理服务组成,包括硬件组件、SQL接口组件、查询分析器组件、优化器组件、缓冲区组件、插件存储引擎、物理文件。
可以看到Mysql由连接池组件、管理服务组成,包括硬件组件、SQL接口组件、查询分析器组件、优化器组件、缓冲区组件、插件存储引擎、物理文件。
小明发现MySQL中的存储引擎是作为插件提供的。 MySQL中有很多存储引擎,每种存储引擎都有自己的特点。然后小明打出命令:
show engines \G;
原来发动机的种类有很多种。
我又写了下面的命令来检查当前数据库的默认引擎:
show variables like '%storage_engine%';
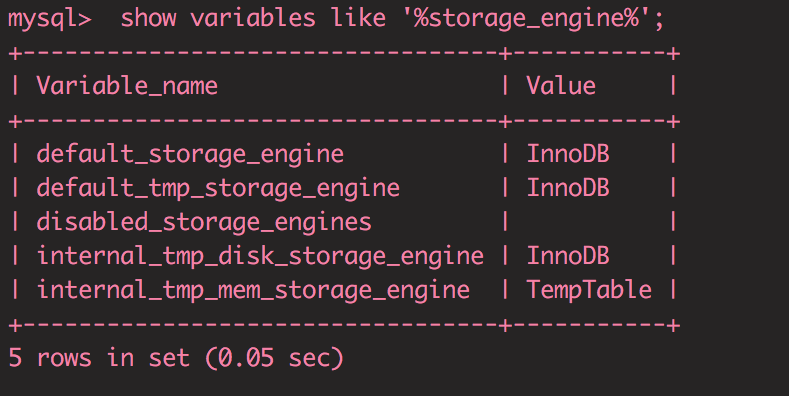 小明恍然大悟:原来他的数据库使用的是InnoDB。他依稀记得上学的时候听说过一个叫MyIsAM的引擎。小明想知道两者有什么区别?我立即查看了信息:
小明恍然大悟:原来他的数据库使用的是InnoDB。他依稀记得上学的时候听说过一个叫MyIsAM的引擎。小明想知道两者有什么区别?我立即查看了信息:
| 比较项 | InnoDB | MyIsAM |
|---|
| 事务 | 支持Nock | 支持MVCC行锁 | 桌面锁 |
| 国外游戏 | 支持 | 不支持 |
| 存储空间 | 存储空间 由于需要缓存,可以压缩 ›❀ 更大的场景 | 很多更新和插入 | 很多选择 |
小明明白InnoDB 和 MyISAM 之间的区别。自从使用了InnoDB,小明就不用太担心了。
2.2 交易的隐私性
小明在研究锁之前,想起了他在学校时教过的数据交换的隐私性。事实上,数据库中锁的作用之一就是实现隔离。事务隔离主要用于解决脏读、不可恢复读、幻读等问题。
2.2.1 脏读
一个事务读取未从另一个事务接收到的新数据。这是什么意思?
| 时间点 | 交易a | 交易b |
|---|
| 1 | 开始; | |
| 2 | 从 id = 1 的用户中选择 *; | 开始; = 1; |
| 4 | select * from user where id = 1; | |
| 5 | commit; | commit; |
A在事务A和B中,事务A分别在时间2和4提交给用户。查询了表中的=1,但是事务B在时间3被修改了,结果事务A在时间4请求的结果实际上被事务B修改了,破坏了数据库的隔离性。
2.2.2 不可重复读取
在同一个事务中,多次读取相同的数据会得到不同的结果。与脏读的区别在于,这里读取的是已经完成的内容。
| 时间线 | 事务A | 事务B |
|---|
| 1 | 开始; | |
| 2 | 从id=1的用户中选择*; | 设置用户;️id = 1; | |
| 6 | commit; | |
事务B发送的事件在事务A的第二次查询之前,但事务B仍然被读取,更新结果破坏了事务隔离。
2.2.3 幻读
一个事务读取另一个事务提交的输入数据。
| 时间点 | 事务A | 事务B |
|---|
| 1 | 开始; | |
| 2 | 从id > 1的用户中选择*; | 开始;插入;; |
| 5 | select * from user where id > 1; | |
| 6 | commit; | |
在事务A中,大于1的ID被查询了两次。第一个查询结果中没有id大于1的数据,但是由于事务B插入了ID=2的分片,导致事务A在第二次申请的时候看到了事务B插入的数据。
事务隔离:
| 隔离级别 | 脏读 | 不可撤销读 | 隐式读 | NO | 否 | 否阅读承诺 (RC) | YES | NO | NO |
|---|
| 重复读取 (RR) | YESYES 可串行化 | YES |
小明注意到,在数据采集过程中,写入InnoDB的数据略有偏差与其他数据库不同。重复读取InnoDB可以解决幻读,小明心想:这个InnoDB很好啊,我得仔细看看它是怎么工作的。
2.3 InnoDB 的锁类型
小明先了解一下Mysql 中常见的锁类型:
2.3.1 S 也叫双读写锁:♶ 读锁。其他事务可以继续添加共享锁,但不能继续添加私有锁。
X-排它锁:也称为写锁。一旦添加了锁,就无法锁定其他事务。 一致性:指当事务A获得某一行的锁时,事务B也尝试获得该行的锁,如果立即获得,则称为锁兼容性,否则称为战争。
纵轴表示现有的锁,横轴表示尝试获取的锁。
| . | X | S |
|---|
| 2.3.2 意向锁 InnoDB 中的意向锁是一张表。就像它的名字一样,它用来表明交易想要实现的目标。分为: - 共享锁意图:表示事务想要获得表中某些行的共享锁。
- 意向排它锁:表示事务想要获得表中某些行的排它锁。
这个锁是做什么用的?为什么需要这把锁?首先,如果没有这样的锁,如果要给表加表锁,一般的方法是遍历每一行,看是否有行锁。这不是很有效。如果我们有意向锁,我们需要判断它是否有行锁。只要有意图锁,就不必逐行查看。 在InnoDB中,由于支持行锁,InnboDB的锁同步可以扩展如下: | . | IX | IS |
|---|
| 1 | ♾ 冲突 冲突 | 冲突 | | S | 冲突 | 对应 | 冲突 | | 1 | 兼容 .3自动增加锁机械锁,提高并发插入性能。这个锁有几个特点: - 当sql完成时锁被释放,并不意味着事务完成。
- 对于Insert...select来说,插入大量数据会阻塞其他事务的执行,从而影响插入的性能。
- 自动增量算法是可配置的。
MySQL 5.1.2版本之后,有很多改进,可以通过不同的方式配置自增锁方式。小明看到了,打开自己的MySQL,发现5.7之后,输入如下语句来获取当前的锁模式: mysql> show variables like 'innodb_autoinc_lock_mode';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_autoinc_lock_mode | 2 |
+--------------------------+-------+
1 row in set (0.01 sec)
在MySQL中,innodb_autoinc_lock_mode有三种配置方式:分别是0、1、2。 “传统模式”、“连续模式”、“交错模式”。 - 传统模式:即采用桌面锁。
- 连续模式:插入时如果可以指定行数则使用互斥量,如果不指定行数则使用表锁方式。
- 互锁模型:全部使用互斥体。为什么称为交错模式?自增值在批量输入期间可能不会持续存在。当然,一般情况下,如果你不看重不断自增的价值,一般都会选择这种方式。演出是最好的。 OK
2.4 InnoDB锁算法小明学习了InnoDB中可用的锁类型,但是如何使用这些锁仍然取决于锁算法。 2.4.1 记录锁定 记录锁定记录。这里需要注意的是,这里锁定的是记录,而不是实际的记录。 - 如果锁是非主键索引,则会先用自己的索引加锁,然后再用主键加锁。
- 如果表上没有索引(包括没有主键),则使用秘密主键。
- 如果没有引用要锁定的列,则整个表记录将被锁定。
2.4.2 间隙锁 间隙锁顾名思义是锁定间隙,但不锁定记录。缩小差距意味着封闭一个区域。间隙锁也称为间隙锁。它不会阻止其他锁间隙,但会阻止引入锁间隙。这也是避免幻读的关键。 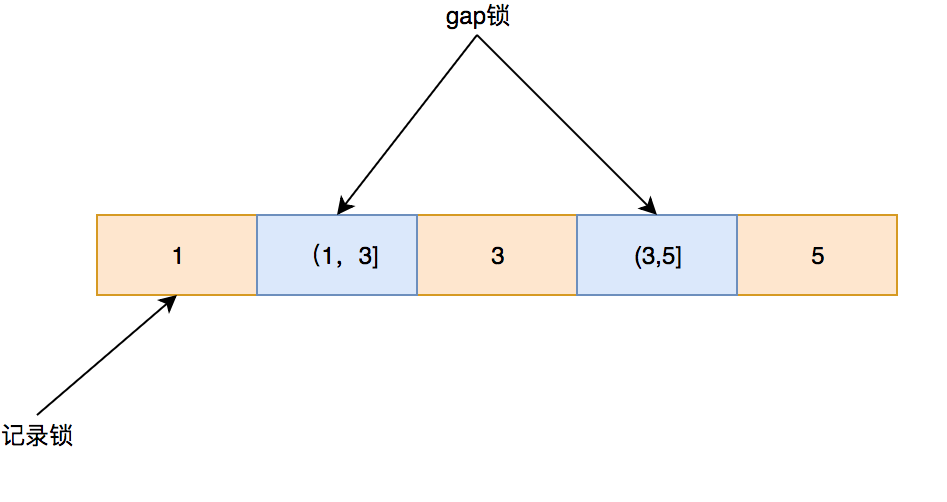
2.4.3 下一个按键锁这个锁实际上是文件锁加范围锁。在RR隔离级别(InnoDB默认)下,Innodb使用该算法进行行扫描锁,但是如果查询扫描中存在单个索引,则会失败,除非仅使用文件锁。为什么?因为单个索引可以确定行数,但其他索引无法确定行数,因此很有可能在另一个事务中再次添加该索引中的数据,从而造成幻读。 这也解释了为什么Mysql可以在RR级别解决幻读。 2.4.4 插入意向锁 插入意向锁 Mysql 官方解释: 意向锁是一种由 INSERT 操作设置的锁间隙。此锁指示以这样的方式插入的意图:插入到参考区间的多个事务不需要相互依赖,除非它们被插入到区间中的同一位置。假设有值为 4 和 7 的记录,停止尝试分别输入值 5 和 6 的事务,每次关闭 4 和 7 之间的间隔,并关闭前一次尝试来获取私有锁。要插入的行,但不要彼此靠近,因为行不重叠。当多个事务同时向同一个索引空间写入不同的数据时,无需等待其他事务完成,也不会发生锁等待。假设有一个基值为4和7的记录索引,不同事务分别插入5和6。每个事务将生成 4-7 个插入意向锁并获取插入行独占的锁,但不会被锁定,因为数据行不重叠。 这里需要说明的是,如果存在块锁,就会阻塞意向锁的插入。 2.5 MVCCMVCC,多版本并发控制技术。在InnoDB中,每行记录后面都会添加两个隐藏列,用来记录创建数和删除数。通过使用版本号和行锁,提高了数据库结构的性能。 在MVCC中,读操作可以分为两种: - 图像读取:读取历史数据,简单的select语句,无锁,MVCC实现可重复读取,利用MVCC机制读取提交的数据。取消中。所以读起来不会被阻塞。
- 当前正在读取:当前正在读取要锁定、更新、插入、删除、选择...更新等的语句。
对于RR隔离级别下的快照读取,不以事务开始时间作为快照生成点,而是以第一个select语句的时间作为镜像创建时间。下一个选项将读取当前快照的值。 为低于 RC 隔离级别读取的每个映像创建一个新映像。 特殊的规则是每一行都会有两个隐藏字段,一个用于记录当前事务,另一个用于记录指向Undolog的返回。您可以使用 undolog 读取以前的图像,而无需创建单独的记录位置。 3。锁分析 小明此时学到了很多关于mysql锁的基础知识,所以他决定自己创建一个表来测试。首先,创建了一个简单的用户表: CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(11) CHARACTER SET utf8mb4 DEFAULT NULL,
`comment` varchar(11) CHARACTER SET utf8 DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
设置了许多实验数据: insert user select 20,333,333;
insert user select 25,555,555;
insert user select 20,999,999;
选择性作弊数据库rr 3.1打开了两项交易和实验1.时间点| T触点A | 事务B | | | 1 | start; | | | 2 | select * from user where name = '555'进行更新; | start; | | 3 | | 31,'选择用户'556'; | | 4 | | ERROR 1205 ( HY000):超过锁定超时;尝试重新启动事务 |
小明打开了两个事务,进入上面的语句,发现事务B居然超时了。小明看着他,我明明锁定了=555行的名字,为什么我输入=556的名字却被阻止了?于是小明打开命令提示符,输入: select * from information_schema.INNODB_LOCKS
他发现事务A中的下一个钥匙锁上加了555,事务B插入时,先插入了意图插入锁,于是他得出以下结论: 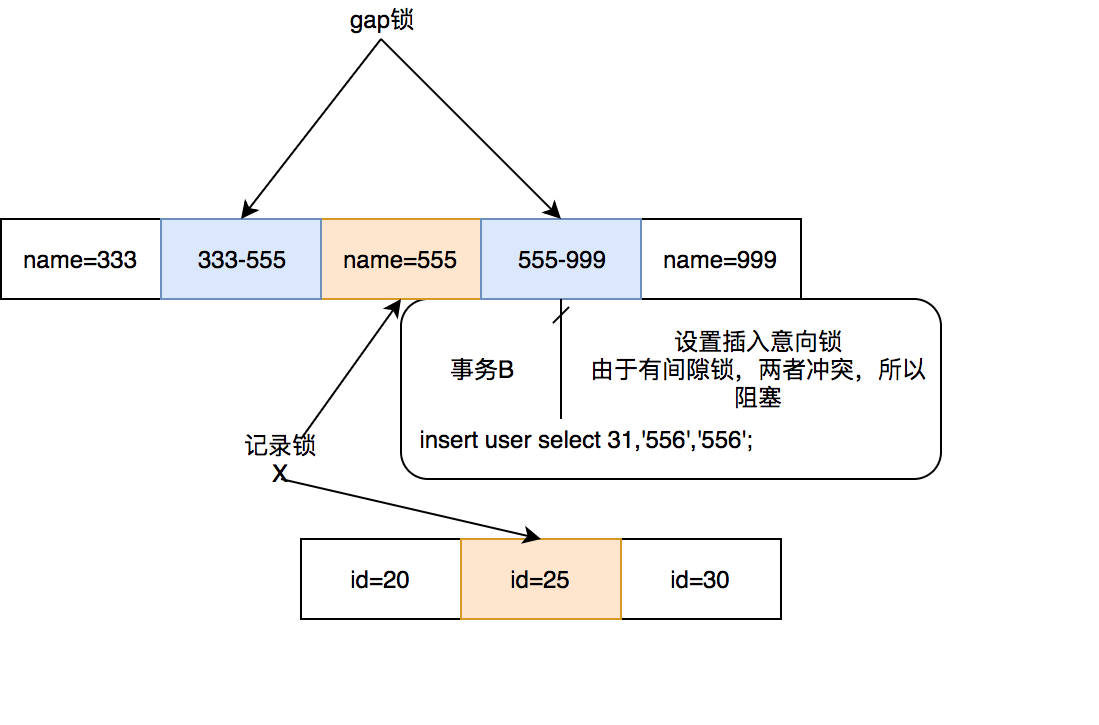 可以看到事务B由于间隔锁和插入意向锁冲突而被阻塞。 可以看到事务B由于间隔锁和插入意向锁冲突而被阻塞。 3.2 实验2小明发现上述查询条件使用了非唯一的通用表示法,于是小明尝试了主键表示法: | 时间线❀❀ ❀ begin ; | |
|---|
| 2 | select * from user where id = 25 for update; | begin; | | 3 | | insert user select 26,'666','666'; | | 4 | | 查询OK,编号1受影响(0.00秒); 记录:1 重复:0 警告:0 我看到事务 B 没有被阻止。出了什么问题?小明有些困惑。按照实验1的方法,应该是被阻塞的,因为25-30之间会有差距。因此,小明再次使用命令行,发现只加了X文件锁。事实证明,只需一个指纹即可解锁记录。这样做的原因是:因为非唯一索引加上后续的键锁无法确定确切的行数,其他事务可能会在你的查询过程中重新添加这个索引的数据,从而侵犯隐私,即幻读。 。因为唯一索引标识唯一的数据行,所以不需要添加锁间隙来解决幻读。 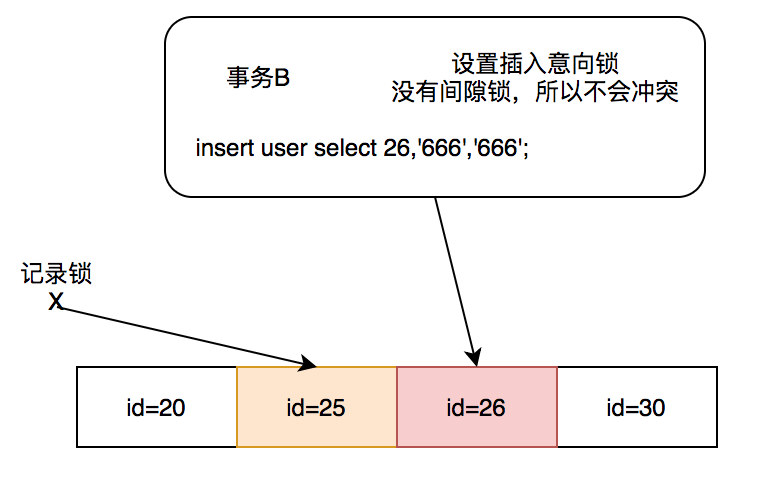
3.3 实验3上面测试了主键索引和非唯一索引。非索引域也可用。如果关闭会发生什么? | 时间点 | 交易A | 交易B |
|---|
| 1 | 开始; | | | 2 | 从评论 = '555'的用户中选择*进行更新;; 666','666'; | | 4 | | EVERY 1205 (HY000):超出锁定超时;尝试重新启动事务 | | 5 | | 输入用户选择31,'3131','3131'; | | 6 | | ERROR 1205 (HY000):超出锁定超时;尝试重新启动事务 | | 7 | | 输入用户选择10,'100','100'; | | 8 | | ERROR 1205 (HY000):超出锁定超时;再尝试谈判 |
小明看着他,哦,放开我吧,怎么回事?无论我使用实验1的非斜率锁定域中的数据还是斜率中的数据,它都不起作用。是否可以添加表锁? 事实上,如果您使用非索引数据库,则会向所有聚集索引添加后续锁。 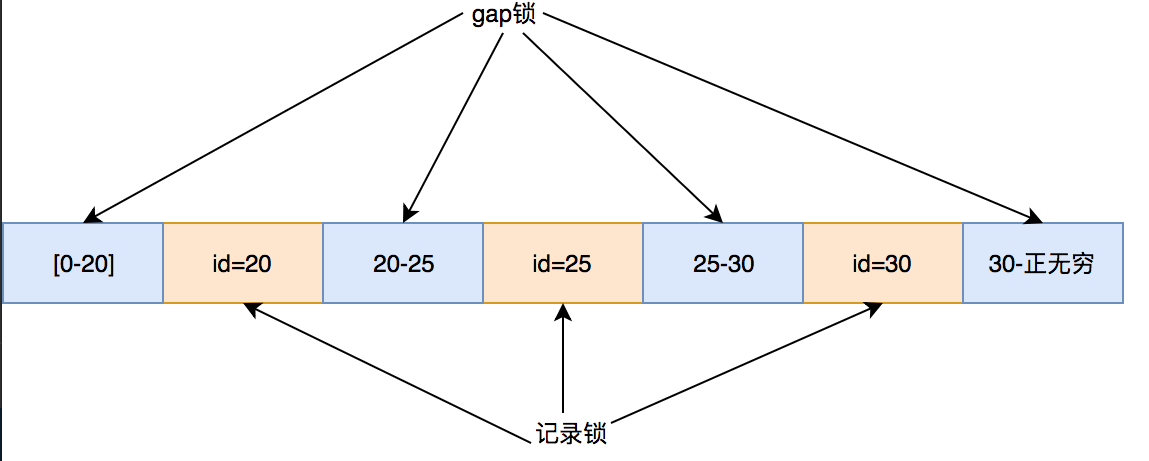
所以当你经常开发的时候,如果需求没有索引,你就必须做一个不断的读,也就是封闭读,这会让整个表被索引,这会让所有其他事务被阻塞,并且数据通常不可用。状态。 4。回到危险4.1死锁小明完成实验后,终于明白了死锁的一些基本方法,但是以前网上出现的死锁是什么呢? 流量:指两个或多个相互依赖的事务在执行过程中竞争资源的现象。说明无人等候就会停电。可以通过消除等待来解决死锁,例如重试事务。 解决死锁的两种方法: - 等待超时:当一个事务等待超时并返回该事务时,就可以执行另一个事务。然而,这样效率并不高,并且会导致等待时间。一个问题是,如果这笔交易非常繁重,有大量数据正在更新,但随后又重复,就会造成金钱的浪费。
- 等待图:等待图用于描述事务之间的等待关系。当这个图中出现一个循环时,它看起来像这样:
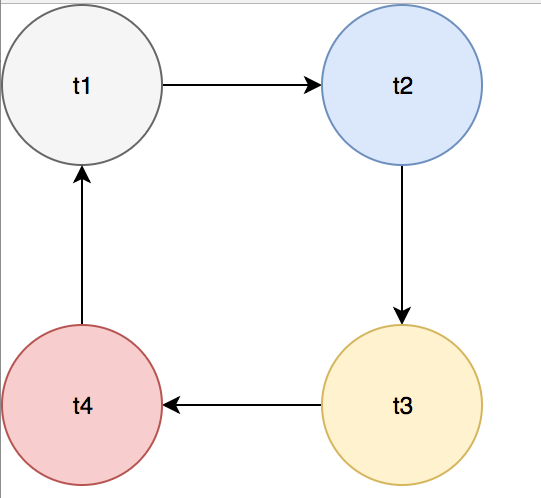 就会有一个返回。默认情况下,InnoDB会选择返回值。销量减少抵消了销量减少。 就会有一个返回。默认情况下,InnoDB会选择返回值。销量减少抵消了销量减少。
4.2 在线提问 至此,小明已经具备了所有他需要的基本技能,所以他开始在本地表中重复这个问题: | Tiptime | | |
|---|
| 1 | | | 1 | 开始; | 开始; | | 2 | 从名称='777'的用户中删除; | 从名称='666'的用户中删除; | | 3 | 输入用户选择27,'77777,''; | 输入用户选择26,'666','666'; | | 4 | ERROR 1213 (40001): 尝试锁定时快速找到;尝试再次开始交易 | 查询OK,命中1个号码(14.32秒)记录数:1重复数:0警告数:0 |
可以看到交易A已经延迟,交易B已经成功完成。到底是什么?每次都发生了什么? 第2点:事务A删除name='777'的数据。我们需要给索引777加锁next-Key,但是没有,所以只锁555-999之间加了一个间隙锁。同样,事务B在555-999之间加了一个间隙锁。锁间隙相互兼容。 时间点3:事务A先进行Insert,插入锁,但555和999之间有间隙。由于锁意向锁和间隙锁冲突,导致块和事务A等待事务B插入释放虚空锁。事务B也做同样的事情,等待事务A释放间隔锁。然后出现A->B,B->Awaiting循环。 时间线4:事务管理器选择回滚事务A,事务B成功执行。 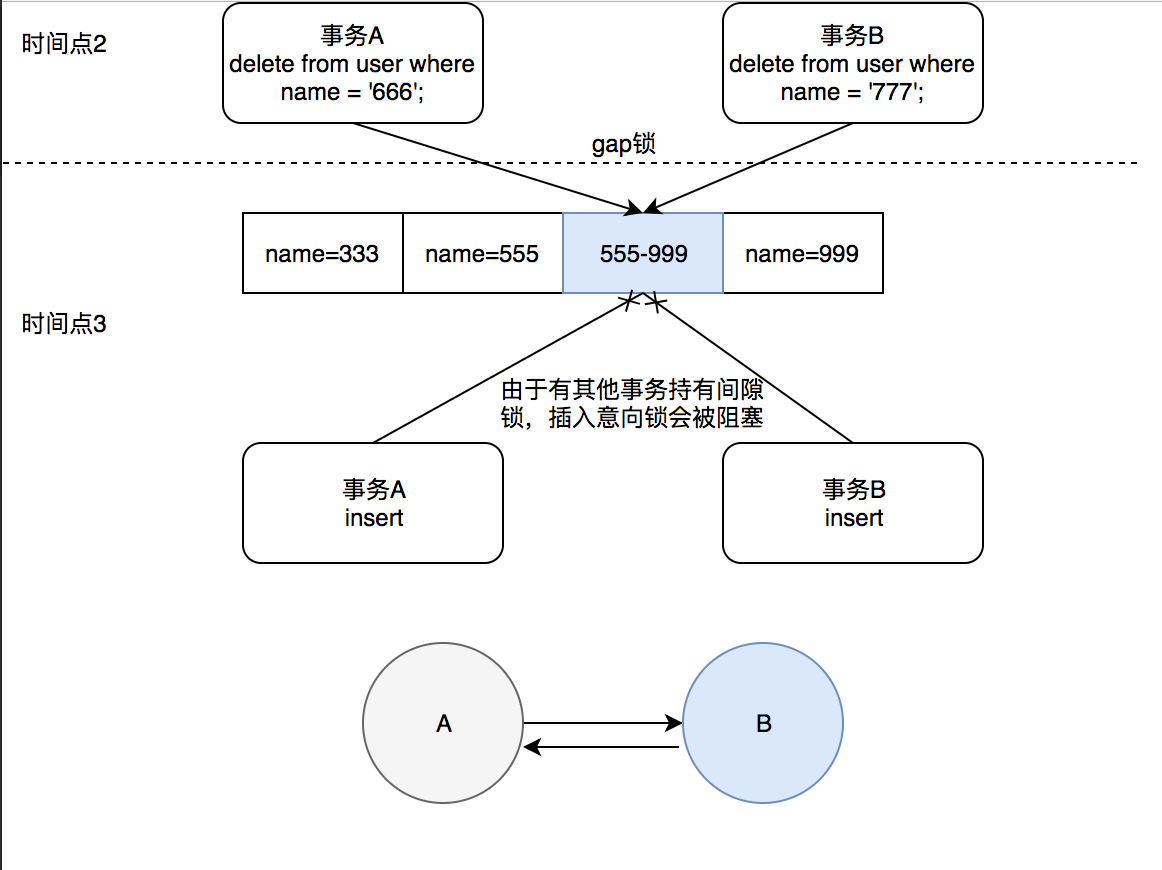
4.3 BUG修复这个问题只有小明才发现。这是因为真空锁。现在我们需要解决这个问题。造成此问题的原因是间隙闭合,因此我们将其删除: - 解决方案 1:将隔离级别降低到 RC。在RC级别以下,不会添加锁间隙,所以不会有问题。但低于RC级别,会出现幻读,提交读会破坏隔离问题,所以这个方案行不通。 。
- 选项 2:将隔离级别提高为可串行化。经过测试,小明发现这个问题不会发生,但是在可序列化级别,性能会更低,锁等待会更多,就不会发生了。考虑。
- 选项 3:更改代码逻辑。不要直接删除。使用业务逻辑编辑每个数据项,以确定更新哪些数据、删除哪些数据以及添加哪些数据。这个负担有点大了。小明写下了这个直接删除的逻辑。为了不做这些复杂的事情,这个时候就不考虑这个计划了。
- 选项 4:修改代码逻辑较少。删除前可以通过快照查询(不加锁)。如果问题没有得到解答,请直接发帖。如果存在使用主键的删除,在前面第3节实验2中,单个索引将被简化为记录锁,因此没有间隙可以关闭。
考虑之后,小明选择了第四个选项,立即修复,然后上网查看确认。他发现这个bug没有再出现了。现在小明可以安心睡觉了。 4.4 如何避免停电 小明通过基础学习和共同经验总结出以下几点: - 按固定顺序输入表格和行。交叉访问可能会导致等待循环。
- 尽量避免大交易。资源锁定得越多,就越容易发生停机。建议将其分解为小任务。
- 降低隔离级别。如果公司允许(根据上面4.3的分析,有些公司不允许),降低隔离级别也是一个更好的选择。例如,将隔离级别从 RR 调整为 RC 可以防止许多由间隙锁引起的中断。 。
- 向表中添加适当的索引。防止在没有索引的情况下发生表锁,死锁的概率会突然增加。
|
|
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。
 code前端网
code前端网




