 code前端网
code前端网MySQL主从复制、读写分离架构延迟较长,如何优化?
MySQL主从复制、读写分离是互联网上常见的数据库架构。这种架构最受诟病的地方就是在大数据量、大并发的情况下。这种场景下,主从延迟会很严重。
为什么主从延迟这么大?
![]()
解答:MySQL使用单线程重播RelayLog。
我们应该如何优化并缩短回放时间?
解答:多线程并行重复RelayLog可以缩短时间。
RelayLog多线程并行重复有什么问题? ? 为什么会出现不一致的情况?
解答:如果将RelayLog随机分配到不同的重播线程中,假设RelayLog中有3条串行修改记录:
update account set Money=100 where uid=58;=setup account Money 150 where uid =58;
update account set Money=200 where uid=58;
如果单线程串行重播:可以保证所有从库的执行顺序与主库一致。
画外音:最后钱是200。
如果随机分配多个线程来玩:多个重放线程同时执行这三个语句,不确定谁最后运行,谁最后运行从库数据可能与主数据库不同。
画外音:几个奴隶库可能有100、150、200的钱,不确定。
如何分配播放多个从库和多个线程以获得一致的数据?
响应:同一个库的写操作可以被同一个线程重放;不同库上的写操作可以使用多个线程同时进行。
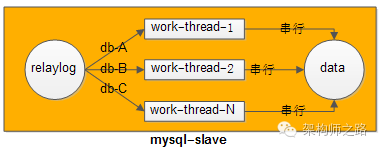
怎么办?
Ans:设计一个哈希算法,hash(db-name) % thread-num,对库名进行哈希然后调制线程数,就可以轻松对同一个库进行写操作,串行执行相同的重复线程。
画外音:不同库并行播放,提高播放速度。
这个计划有哪些缺点?
解答:很多公司对于MySQL都是使用“单库多表”。如果真是这样的话,那仍然只是一个数据库,仍然无法提高RelayLog的回放速度。
披露:将“单库多表”数据库架构模型升级为“多库多表”数据库架构模型。
旁白:在大数据量、高并发的互联网业务场景中,“多数据库”模型还具有很多其他优势,例如:
(1)非常方便的实例扩展:DBA可以轻松地将不同的库扩展为不同的实例;
(2)按业务进行库隔离:业务解耦、业务隔离,减少耦合和相互影响;
(3) 共享微服务非常方便:每个服务都有自己的。例子很实用;
“单库多表”场景下多线程并行播放如何优化?
解答:虽然只有一个数据库,但是事务是在主数据库上并发执行的。既然可以在主库上并行运行,那是不是也可以在从库上并行运行呢?
新想法:将主数据库上并行执行的事务分成一组并编号。这些事务在从库上的回放是可以并行进行的(主库上事务的执行全部进入准备阶段,说明事务之间不存在冲突,否则无法提交),是的,MySQL正是这样做的。
解决方案:基于GTID的并行复制。
从 MySQL 5.7 开始,组提交的信息存储在 GTID 中。使用mysqlbinlog工具,可以看到批量提交里面的信息:
20181014 23:52 server_id 58 XXX GTID last_comfilled=0equence_numer=1
20181014 XXX GTID: 5_824 server 23 =2
2018 1014 23: 52 server_id 58 XXX GTID last_comfilled=0 sequence_numer=3
20181014 23:52 server_id 58 XXX GTID last_commiss=4 ♻是last_comfilled和sequence_number多的原始序列号。
last_commited 是什么?
答:事务提交时,是最后提交的事务号。如果它们的last_commited相同,则说明它们在一个组中,可以同时播放和执行。 ?画外音:例如,许多 crontab 可以使用多线程来共享数据并并行运行。
- 多线程同时提交任务时,必须保证幂等性:MySQL提供了“幂等if library”和“幂等if commit_id”两种方法,值得借鉴;
画外音:比如群组消息,可以根据group_id幂等;根据user_id,用户消息可以是幂等的。 ? 》架构;mysql5.7:根据GTID并行复制;
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。




