 code前端网
code前端网字符串实现和kmp算法讲解:《大话数据结构》学习笔记
2。字符串的逻辑存储
字符串指的是字符串,是一种特殊的线性表。特殊之处在于它只能记录字符,也就是说,它还可以使用顺序或链式记录。下面简单讨论一下两种存储结构的优缺点。
顺序内存
顺序存储使用数组。由于它是一个数组,因此需要固定的空间量。如果需要连接或替换字符串,可以扩展数组。这个操作比较耗时,有时数组空间使用率很低,浪费了一些空间。但优点也很明显,定位快。
连锁仓储
连锁仓储不受房间大小限制。您可以根据需要链接任意数量的节点以及所需的空间。但如果每个节点只存储一个字符,那绝对是浪费空间。如果存储多个字符,则查找字符需要花费更多时间,并且链表本身查找速度也很慢。
我的意见
我更喜欢顺序录制。毕竟,对字符串最频繁的操作就是搜索功能。相比链式存储,牺牲了一些空间来换取更快的查询速度。
3。应用字符串 - 暴力搜索
让我们来谈谈应用字符串:搜索子字符串。这应该很熟悉。有许多应用场景需要从父字符串中查找子字符串。您可能想要查找子字符串的位置,或者确定它是否存在,或者替换它、替换全部等。为此,我们需要执行最基本的操作来查找子字符串。
下面的例子对我们来说可能是最简单的算法。随便找找看:两个循环是嵌套的,外层循环(i)逐一遍历父字符串中的每个字符,判断是否与子字符串中的第一个字符匹配。如果匹配,则继续评估第二个字符,直到遍历并找到子字符串。但是,如果该字符在中间不匹配,我会搜索回原始匹配项以匹配下一个字符的第一个字母。基本流程如下:
`public static int matchPattern(String origin,String aim) {
char[] origins = ();
char[] aims = ();
for(int i = 0; i < origins.length; i++) {
int j = 0,k = i;
for( ; j < ) {
if(origins[k] != aims[j]) {
break;
}
}
if(j == ) {
return i - j;
}
}
return -1;
}`这个方法应该是可以想象的,但是这样写是有问题的。问题是这样的:
看起来很正常,但是如果你仔细观察,你会发现当匹配开始成功时,由于字符不匹配,你必须返回并重新开始。如果字符串很长和目标相似度很高,则重复这样的比较。重要的是,我们实际上可以根据已知的比较结果减少比较次数来优化这个算法。
4。 KMP算法
简单说一下这个算法的背景以及KMP的由来。
KMP 算法是 、 等人发现的一种高级字符串匹配算法,因此人们称之为 Knut-Morris-Pratt 运算(简称 KMP 算法)。
用我自己的话说,总结就是,在字符串匹配的时候,由于某个字符无法匹配,所以从匹配成功的字符串中计算出下一个子串要移动的位置,从而达到减少不必要的匹配,实现快速匹配。那么关键点来了,如何计算子串需要移动的位置呢?我怎么知道这样的举动之后不会有任何遗漏呢?下面我们一起来分析一下(还是用上面的例子,为了方便描述,我们将主字符串称为o(origin),子字符串a(目的))。
- 这样搭配第一步就不成问题了。
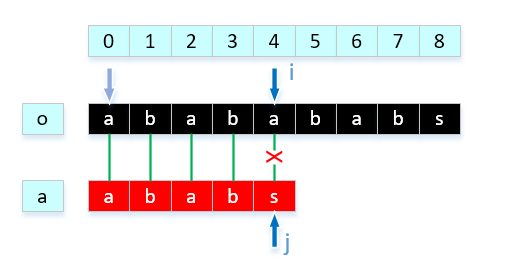
- 在第二阶段,出现匹配问题。问题是我在上一步中移到了4(数组的下标)。由于 o[4] != a[4],所以这次匹配失败。必须找到 i 回到 1,j 回到 0 以及之前的比赛结果信息,这根本没有帮助。
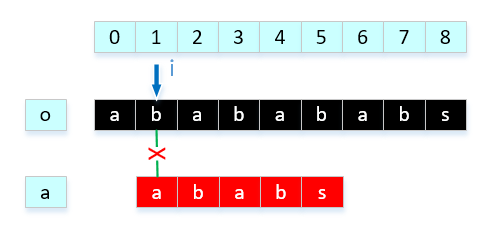
由于根据对应信息 o[0] = a[0],o[1] = a[1], o[2] = a[2], o[3] = a[ 3 ],前4个数字是等价的,o[2] = a[0], o[3] = a[1],我们可以这样移动它:
这种情况下不需要移动比较o[1]和a[0]、o[2]和a[0]、o[3]和a[1],直接比较o[4]和a[2],省去不必要的步骤。那我们继续分析,显然是o[4]! = a[2],由于o[2] = a[0],o[3] = a[1]和a[0],a[1]不相等,所以我们可以得出o[3]! = a[0],所以这个比较步骤可以省略,直接比较a[4]和a[0]即可。最终的结果是
这个对比方式我们是可以接受的。这消除了许多基于已知匹配信息的比较操作并提高了效率。 - 有人会问,如何知道准确的移动位置,以便将j放到合适的位置呢?这也引出了KMP算法的主要部分,要求如下[]。 next[]的作用是什么?下一个[0],下一个[1]....下一个[n]是什么意思?接下来是保存相应的子串字符冲突后j必须移动到的位置。例如:next[4] = 2,表示子串和主串在位置j=4处不匹配,那么主串i不需要回溯,j直接回溯2进行比较,即接下来计算每个[]的值,我们简单地得到并精确改变j的位置。现在我们了解了next[]的用途,我们来探讨一下next[]是如何计算的。
- 以前面的例子来说明:
o[4] 与 a[4] 相矛盾, 前 4 位匹配相等(主要条件) 如果我们想要 阶段基于前 4位 .在等待计算位置时,应该出现以下两种情况之一。 1:子串的前四个数字彼此不相等(数字a[0]、a[1]、a[2]、a[3]都不相同)。根据上面两个条件(o和a相等)直接可以得出a[0]下次应该直接和o[4]比较。这是因为 a[0] 不等于 o 的前四个字符中的任何一个。 2:子串的前4个字符相等,前缀和后缀也相等,也可以计算位置。输入有关后缀和后缀的知识。
例如字符串“abadaba”
前缀:{“a”,“ab”,“aba”,“abad”,“abada”,“abadab”}
后缀:{“a” , " ba", "aba", "daba", "adaba", "badaba"}
那么最长的后缀和后缀匹配相等的字符串“adaba”。
回到上一个问题,对于字符串“abab”,最长匹配的相等字符串是“ab”。那么我们可以这样理解:
我们来分析一下后缀a的关系,但是假设o和a对应的位置相等,所以前缀a对应后缀a。 o 这样我们就可以直接将 j 移动到 2 个位置。这是基本理论。我们通过代码来实现:public static int[] getNext(String aim,int length) { char[] chars = (); int i = 0,j = -1; //next数组长度和aim长度是相等的,因为每一个字符比较出冲突都需要有对应j的位置 int[] next = new int[length]; //第0个位置前是没有前后缀的,所以next[0]我们规定为 -1. next[0] = -1; //第1个位置不匹配,前面只有一个字符,我们只能把j移动到0. next[1] = 0; //注意:这里 i < length -1,而非是 i < length。原因就是 i在循环内部先++,再赋值,如果是 < length会数组越界。 while(i < length-1) { //判断如果对应字符相等,就累加前后缀相同字符长度 if( j == -1 || chars[i] == chars[j] ) { next[++i] = ++j; }else { //注意:就这一句话,困扰我了2天,也许2是比较菜,不过我在文章中,重点解释一下,见文章。 j = next[j]; } } return next; }
这里是重点
我们不需要o来解决下面的问题,我们只需要它就可以得到它。我们只需要找出a中后缀匹配的长度即可。那么我们的方法就是将a和a进行相互比较。比较过程如下:
- a[0] 与 a[1] 比较,不等于
- a[0] 与 a[2] 比较,等于,next[ ++i ] = ++ j , next[3] = 1。这是什么意思?可以理解为,在第三个字符之前的字符中,前缀和后缀的最大公共长度为1,即有1个公共字符“a”。那么知道这些信息有什么用呢?用法是如果j在位置3不匹配,则直接将j改为1继续比较。
- a[1] 等于 a[3]
- a[2] 不等于 a[4]
2 ] 和一个[ 2]不等于a[4]不等于我们还不能确定具体的公共长度(next[4]的值),接下来我们需要回去比较a[4]和a[1]然后a [4]和a[0],如果这样的情况多了,就变成正常的暴力比较,我们可以根据已有的结果得出结论。 说一个困扰我2天的问题,j = next[ j ]
目前我们计算出的结果:next[ 0 ] = -1, next[ 1 ] = 0, next[ 2 ] = 0, next[ 3 ] = 1, next[ 4 ] = 2。根据算法,j = next[2],j = 0。
我一直认为值 Next[j ]代表一个下标,j要移动,所以我不明白如何将next[4]的值放入next[](how can I put the next character in next[]),它是,next[ next[4]],next[4]明确说明了如果在位置j = 4处出现字符冲突,则j被移动到next[4],也就是说是2,那么next[2]是什么意思呢?也就是说,我真的不明白以下内容[4]]。这两天我一直在思考这个问题,会继续上网搜索,看看是否有人和我有同样的问题。经过一番翻阅,终于感觉有一个合理的答案了。 next[j]也表示后缀的最大长度以及后缀在0~j-1个字符中。如果 next[4] 不匹配,则 next[4] = 2 ,我们知道前 4 个字符的最大公共后缀和后缀长度为 2,那么 next[2] 就是求最大公共后缀和后缀长度前2个字符因为它与自己比较和公共后缀和后缀字符“ab”和i=2,前面的字符是相同的,所以在公共后缀中找到相同的后缀就是在i = 2之前找到它,这是下一个 [2] 的值。我相信这个问题已经在这里得到解答。得到了答案。我认为
next[ ] 的解是 kmp 核心。明白了这一点之后,剩下的内容就不多了。引用代码使用next[]完成基串和模式串的查找。暴力破解代码略有修改。
public static int kmp(String origin,String aim) {
char[] origins = ();
char[] aims = ();
int[] next = getNext(aim,());
for(int i = 0; i < origins.length; i++) {
int j=0;
for( ; j < ; ) {
if(origins[i] != aims[j]) {
//改动
if(j == 0) {
break;
}
j = next[j];
}else {
i++;
j++;
}
}
if(j == ) {
return i-j;
}
}
return -1;
}5。说一下kmp改进计划:
比如有一种情况我们的next[]需要优化。情况就是这样。模式字符串:“aaaaaaab”,显然我们的结果是[]{0,0,1,2,3,4,5,6}。与我们的主字符串“aaaaaaacaa ....”相比,这会导致以下情况:
我们如何解决这个问题?也就是说,如果发现模式字符串中出现连续的相等字符,则令 nextVal[i] = nextInt[j]。解释如下:回到前一个字符必须跟在的位置,因为两组前缀和后缀是匹配的,然后和前一个一样。同样的待遇。
public static int[] getNextVal(String aim,int length) {
char[] chars = ();
int i = 0,j = -1;
//next数组长度和aim长度是相等的,因为每一个字符比较出冲突都需要有对应j的位置
int[] nextVal = new int[length];
//第0个位置前是没有前后缀的,所以next[0]我们规定为 -1.
nextVal[0] = 0;
//第1个位置不匹配,前面只有一个字符,我们只能把j移动到0.
nextVal[1] = 0;
//注意:这里 i < length -1,而非是 i < length。原因就是 i在循环内部先++,再赋值,如果是 < length会数组越界。
while(i < length-1) {
//判断如果对应字符相等,就累加前后缀相同字符长度
if( j == -1 || chars[i] == chars[j] ) {
i++;
j++;
//相较于getNext()改动的地方
if(chars[i] == chars[j]) { // i == j, i+1 == j+1
nextVal[i] = nextVal[j];
}else {
nextVal[i] = j;
}
}else {
//注意:就这一句话,困扰我了2天,也许是比较菜,不过我在文章中,重点解释一下,见文章。
j = nextVal[j];
}
}
return nextVal;
}版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。





