 code前端网
code前端网快速学习和微调:存在哪些预训练模型?
Self-Attention 和 Transformer 从一开始就是自然语言处理领域的后起之秀。得益于全局注意力机制和并行训练,基于自然语言的 Transformer 模型可以轻松编码长距离依赖关系,并且可以在大规模自然语言数据集上并行训练。然而,由于自然语言任务种类繁多,任务之间的差异不是很大,因此模型是针对每个任务单独拟合的。构建大型模型并不划算。在CV中,不同的图像识别任务往往需要建立大型模型,这不够经济。 Prompt Learning提案为这个问题提供了一个很好的方向。
这篇文章是关于NLP的一些关键参考评论[1].
1。 NLP模型开发
过去很多机器学习方法都是基于全监督学习。
由于监督学习需要大量数据才能学习出性能良好的模型,因此在 NLP 中大规模训练数据(指针对特定任务标记的数据)是不够的。因此,在深度学习出现之前,研究人员通常关注特征工程,即利用领域知识从数据中提取好的特征;
深度学习出现后,由于可以从数据中学习特征,研究人员转向架构工程,即通过设计合适的网络结构,向模型引入归纳偏差,有利于。
2017-2019年,NLP模型开始转向新模型(BERT),即预训练+微调(pre-train andfine-tune)。在这种模式下,首先用固定结构的语言模型(LM)进行训练,预训练的方式是让模型完成上下文(例如完形填空)。
因为预训练不需要专业知识,可以在网上收集大文本,直接在LM中进行训练。然后,LM 通过引入额外的参数或微调来适应下游任务。这时研究者转向工程目标,即预训练。练习任务并细化任务以设计更好的目标函数。
2.研究Prompt
2.1 什么是Prompt?
在目标工程过程中,研究者发现下游任务的目的与预训练相关。良好的目标一致性。因此,下游任务通过引入文字提示(textual Prompt),将原始任务目标重构为与训练模型一致的填空题。
例如输入“重构”今天我错过了公交车。”:情绪预测任务。 输入:“我今天错过了公共汽车。我感觉 ___。”其中“我感觉那样”是提示,然后使用LM使用表达情感的单词填空。
我们发现,通过在同一个输入上添加不同的方向,可以执行不同的任务,因此下游任务可以与预训练任务对齐并获得更好的预测结果,快速技术。 。
2.2 训练的模型是什么?
- 左右LM:GPT、GPT-2、GPT-3
- Masked LM:BERT、RoBERTarefix PLM 编码器-解码器:T5、MASS、 BART
2.3 是 什么是快速学习方法?
- 按照指令形式分:完形填空、前缀。
- 按照人手动参与与否。设计,自动(离散,连续)
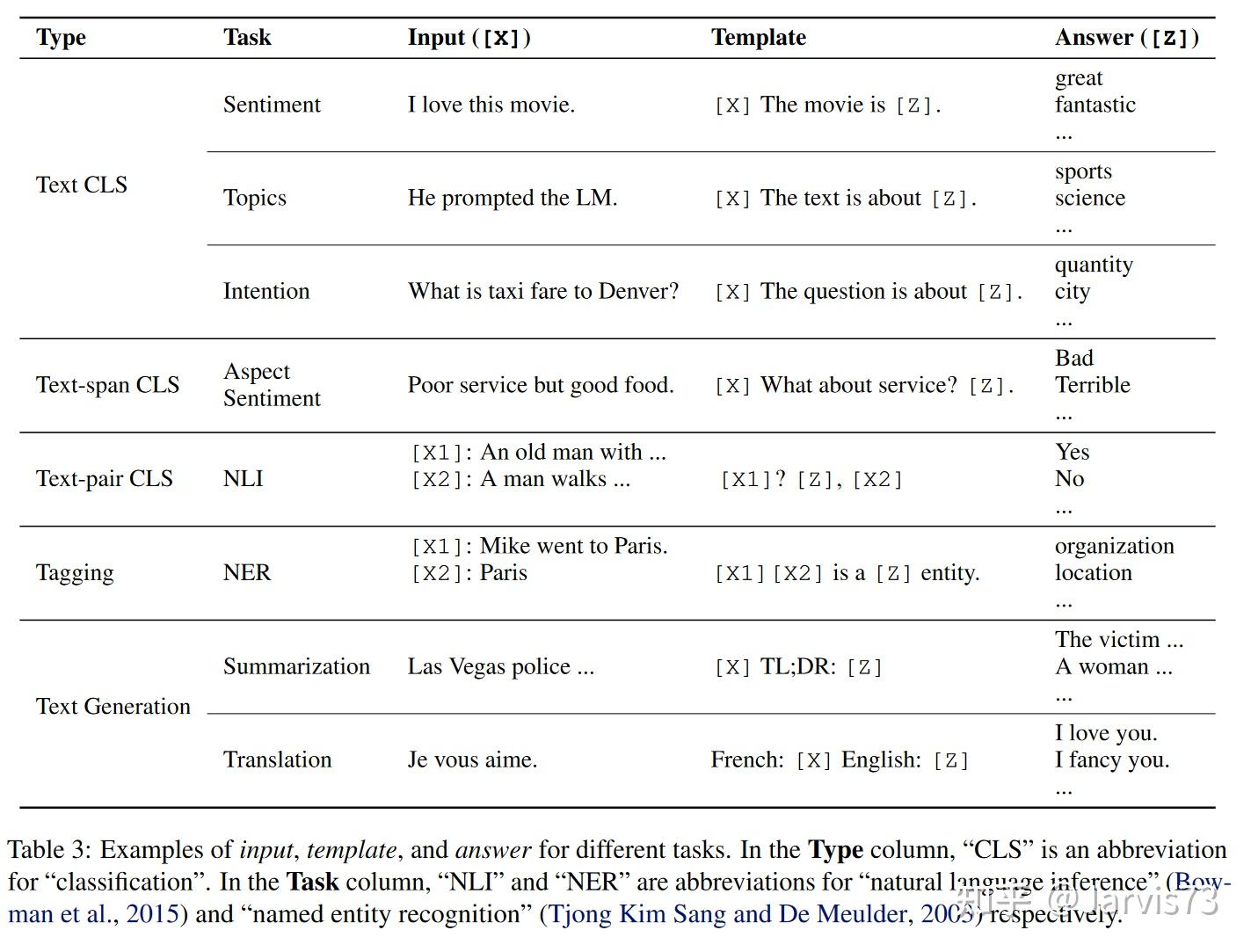 手动设计提示
手动设计提示3。快速调优
3.1 微调策略
在下游任务中对大规模预训练模型进行微调,已经成为很多 NLP 和 CV 任务常用的训练模式。然而,随着模型规模和任务数量的增加,微调所有模型的方法会为每个微调任务保存一份模型副本,使用大量存储空间。特别是当边缘设备上的存储空间和网络速度有限时,共享参数变得很重要。
共享参数的一种更简单的方法是仅设置几个参数,或者向训练好的模型添加一些额外的参数。例如,对于分类任务:
- Linear:只设置分类(线性层),冻结整个主干网络。
- Partial-k:仅设置骨干网络的最后一层k层,冻结其他层[2][3]。
- MLP-k:添加k层MLP作为分类器。
- ]:训练“ side”网络,然后将训练好的特征和“side”网络特征结合起来放入分类器中。
- Bias:仅设置训练网络的偏差参数 [5][6].
:在 Transform 中插入额外的 MLP 模块呃通过残差结构.
近年来,Transformer模型在NLP和CV领域开始流行,Brilliant。在许多 CV 任务中,基于 Transformer 的模型比基于卷积的模型表现更好。
Transformer 与 ConvNet 的比较: Transformer 相对于 ConvNet 的一个显着特点是其在不同空间(时间)上更好的维度操作。
- ConvNet:卷积核在空间维度上进行卷积运算,使得空间中不同位置的特征通过卷积运算融合信息(可以学习),并且只在局部区域进行组合。
- 变形金刚:特点是通过Attention的操作(非学习)将空间(时间)维度的差异进行组合,并进行全局组合。
Transformer 在特征融合中的非学习策略通过添加额外的特征来促进模型的细化。
3.2 NLP 中基于提示的调优
- 前缀调优
- 提示调优
- P-调优
- 基于 P-调优 P-调优 P-调优 P- CV 中的提示调整
3.3.1 分类 分类提示调整 [8]
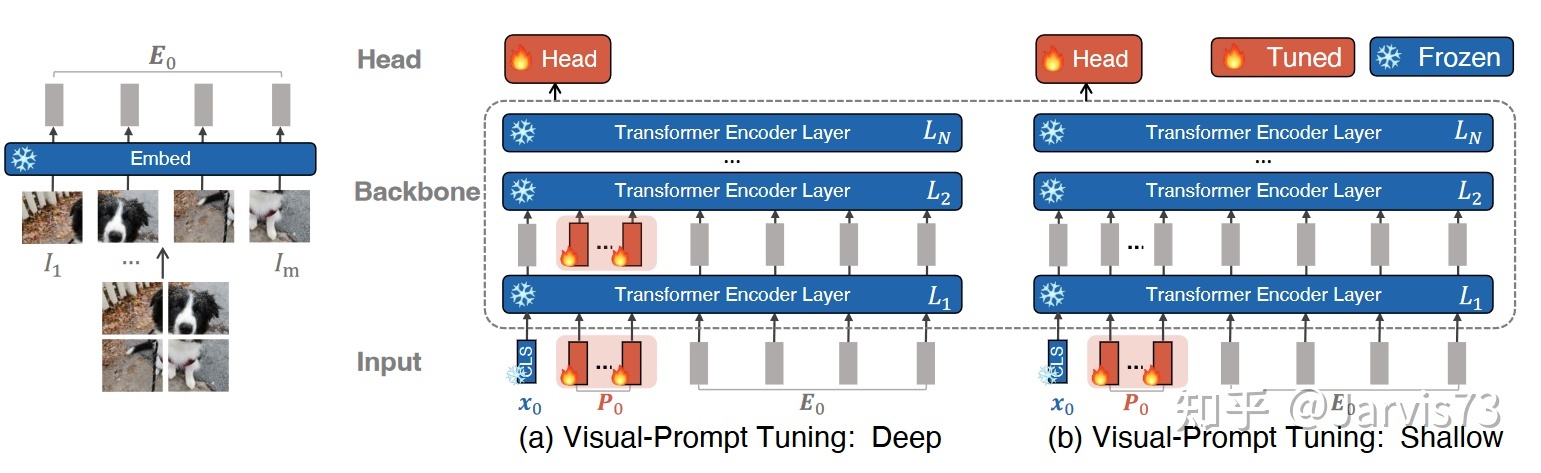 视觉提示调整
视觉提示调整- vpt-cethow
[X1, Z1, E1] = [X0, P, E0 ] )[xi,Zi,Ei]=Li([xi−1,Zi−1,Ei−1])i=2,3,…,Ny=头(xN)
- VPT-深
[ xi ,_,Ei]=Li([xi−1,Pi−1,Ei−1])i=1,2,…,Ny=Head(xN)。通过计算输入特征与每个提示的按钮之间的距离来获得输入与提示之间的距离度量。关键是随着分类目标通过梯度进行优化。
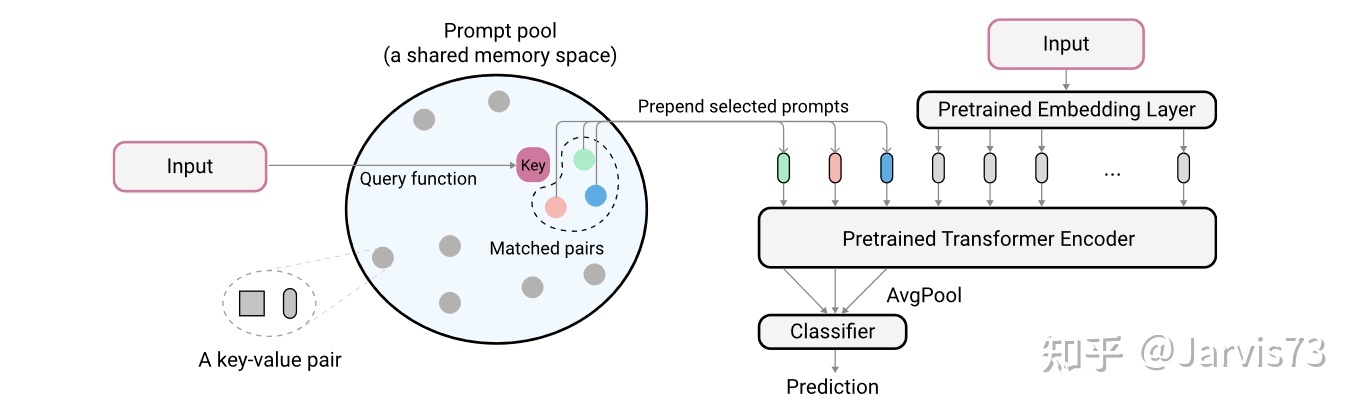 L2P
L2PminP,K,phiL( gphi(fravg(xp)),y)+λΣKxγ(q(x),ksi)
注意,最后使用提示进行分类。3 . 3 多模态模型
视觉语言模型:上下文优化(CoOp)[10]
用于多模态学习的预训练模型。比如CLIP,它通过比较来学习对齐文本和图像特征空间。
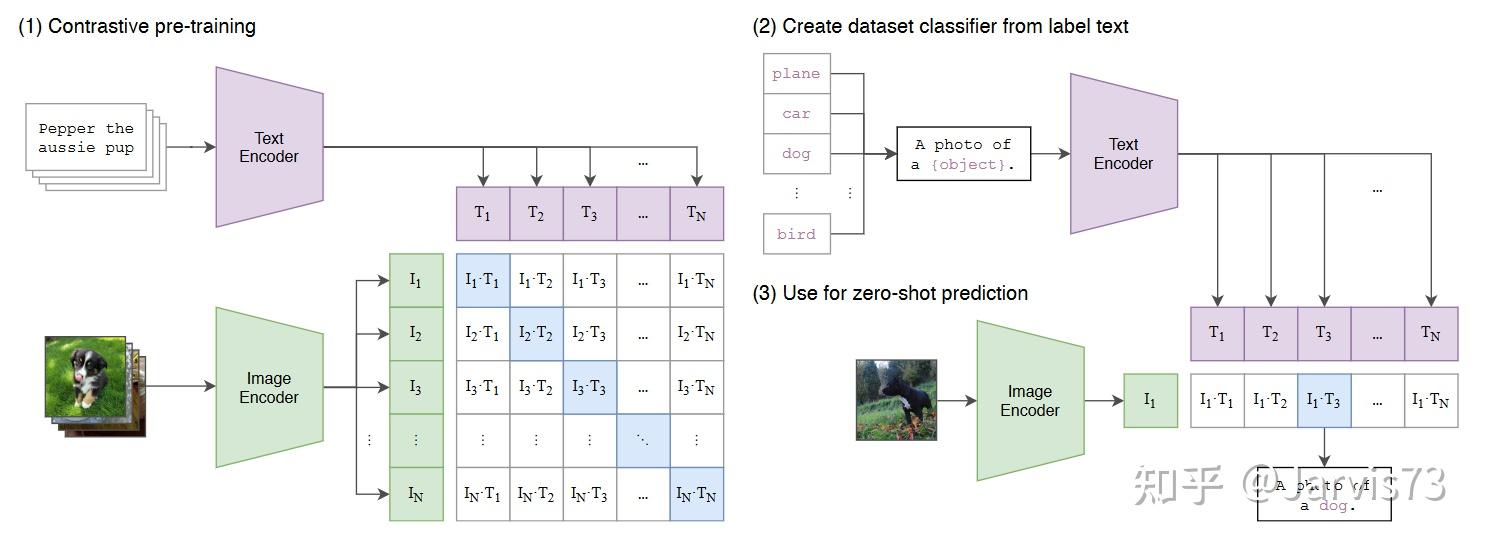 CLIP
CLIP选择不同的文字提示对准确率影响较大。
 提示工程与情境优化(CoOp)
提示工程与情境优化(CoOp)用可学习的提示替换手动设置的提示:‼放在最后:t =[V]1[V ]2…[V]M[CLASS]
- [CLASS] 放在中间:t=[V]1…[V]M2[CLASS] [V] M2+1… [V]M
提示是不同类别之间通用的,您也可以为每个类别使用不同的提示(对于良好的分类任务更有效)。 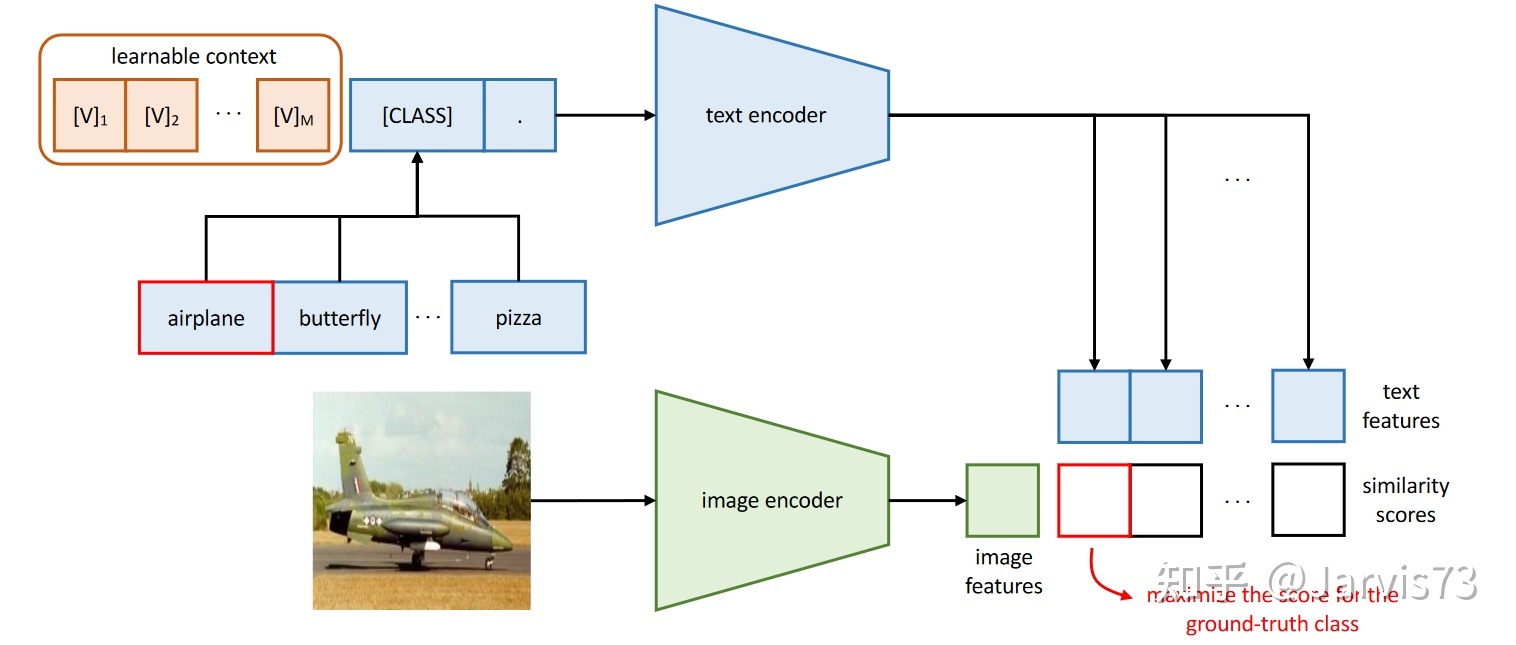 学习创建视觉语言模型
学习创建视觉语言模型 学习创建视觉语言模型
学习创建视觉语言模型
视觉语言模型所需的直接学习❀[]通常不好适应新类别。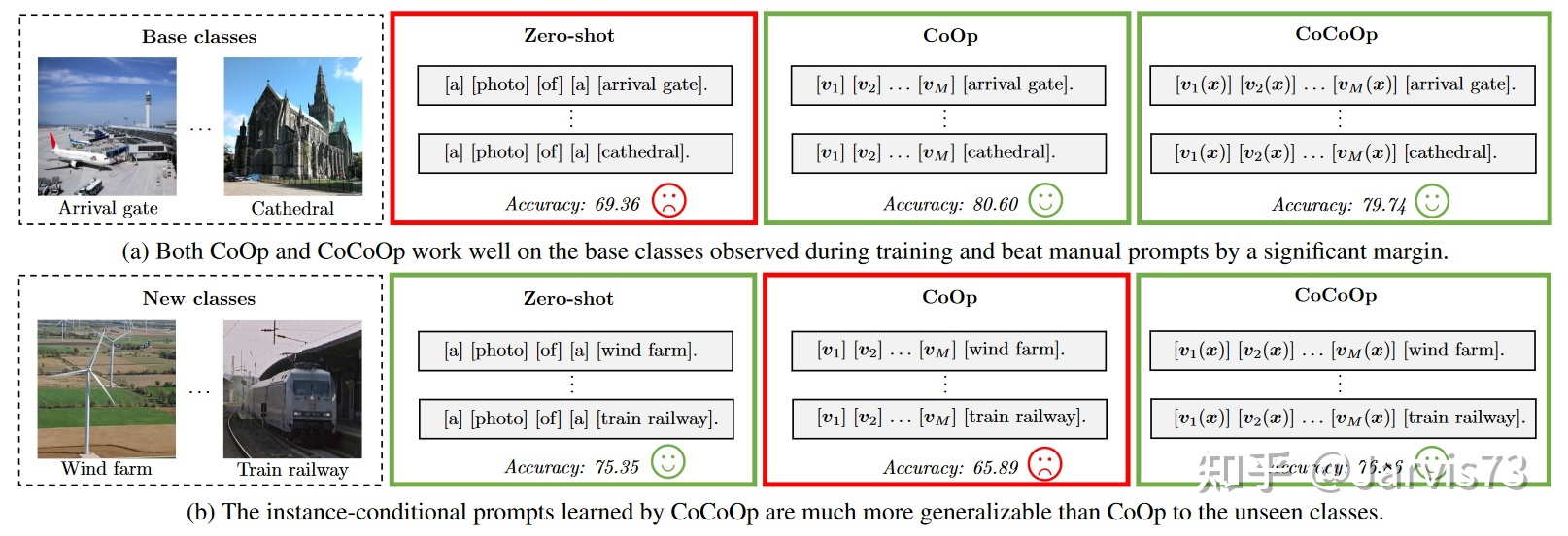 学习可以概括的方向
学习可以概括的方向
所以把方向设计为有条件的示例。 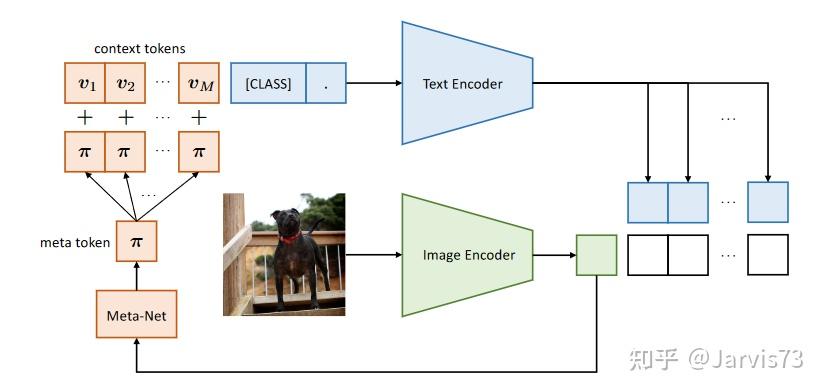 学习一般提示
学习一般提示
将当前与图像相关的特征添加到提示中以提高泛化性能。首先,使用 Image Encoder 计算当前图像的特征,然后使用 Meta-Net 将特征映射到方向的特征空间并将其添加到方向中。 学习可泛化的方向
学习可泛化的方向
3.3.4 领域适应学习提示[12]
使用提示来识别域信息。  提示结构示例
提示结构示例
通过比较学习解耦表示中的类表示和域表示。
P(y^is=k|xis)=exp(⟨g (tks),f(xis) /T) Σd∈{s,u}Σj=1Kexp(⟨g(tjs),f(xis)/T)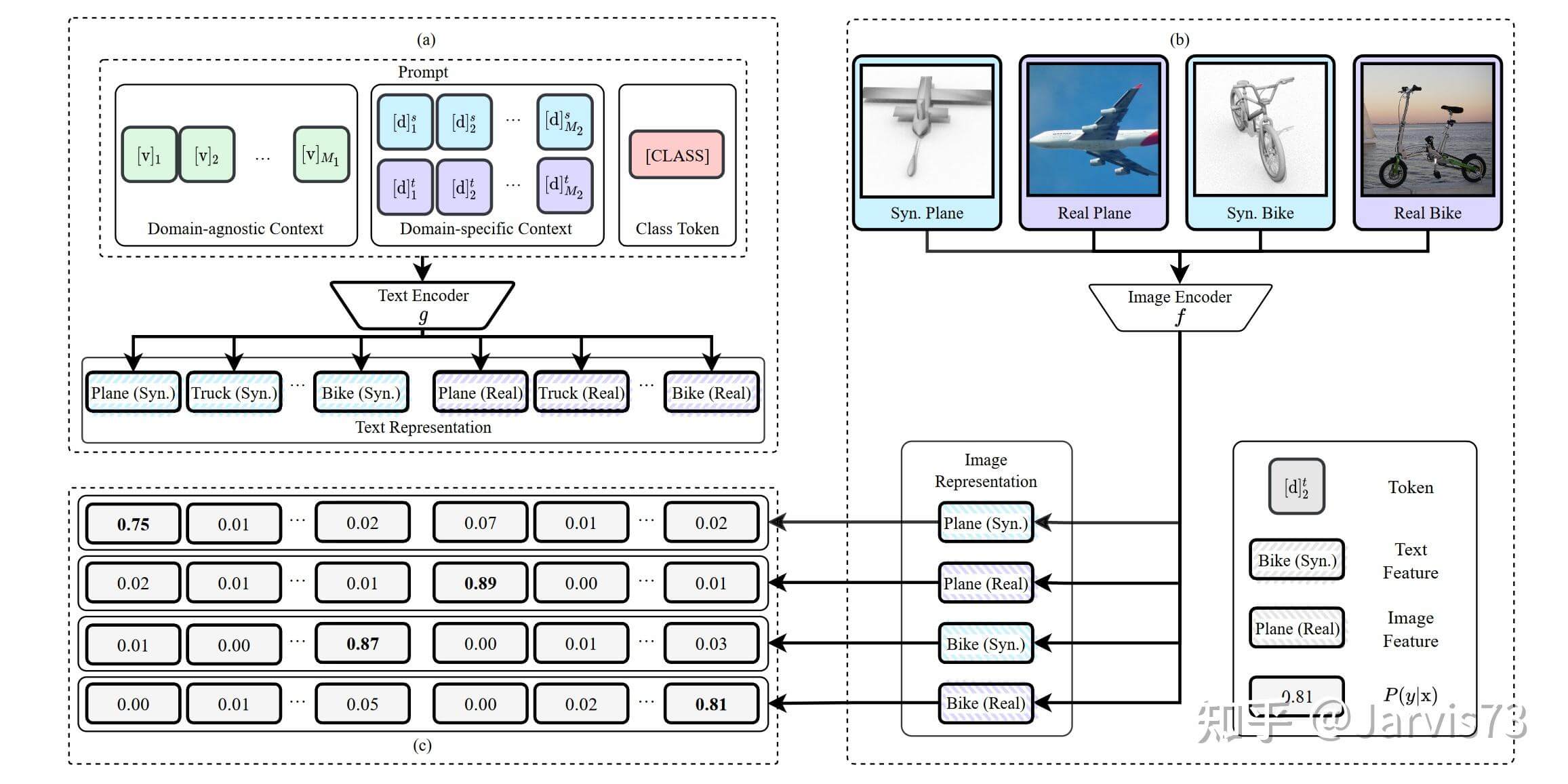 快速学习的领域适应
快速学习的领域适应
参考 -train、Prompt 和预测:自然语言处理提示方法的系统调查。刘鹏飞、袁伟哲、傅金兰、姜正宝、Hiroaki Hayashi、Graham Neubig。在 arXiv 2021 https://arxiv.org/abs/2107.13586
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。






作者文章
- 用小程序学英语到底有没有用?适合哪些人?避坑指南加靠谱用法有吗? 2周前 (05-22)
- 2024-2025做通用和本地生活小程序没人看没人下单怎么办?试试这6个小成本留客转化型技巧 2周前 (05-22)
- 做小程序英文翻译避不开哪些坑?怎么翻才能吸引海外用户留存? 2周前 (05-21)
- Vue3 Composition API watch开启deep后踩过哪些坑?如何高效用它处理深层数据监听? 2周前 (05-19)
- Vue3中watch监听props时,deep:true到底该不该随便开? 2周前 (05-19)