 code前端网
code前端网连续prompt实在不好!谨慎是最好的方法
连续prompt给出了使用大型模型的想法。事实上,这种想法已经见得很多了。 。 。
慎重的prompt是最好的态度,但存在人为设计的模板带来变量的问题。
所以prompt确实不擅长。
如果不想看详细内容,可以直接看摘要。
prompt的三个阶段分别是:
- 第一阶段,离散prompt
- 第二阶段,连续prompt
- 第三阶段,预训练阶段和下游阶段
- 第二阶段,连续prompt
- 第三阶段,预训练阶段和下游阶段
- 第二阶段,连续prompt
- 第三阶段,预训练阶段和下游阶段,零任务类型(零)第三阶段这里是个人意见。
00为什么是prompt
prompt的初衷是,在使用模型进行下游任务时,应该尽可能与预训练模型的pretrain阶段的任务保持一致。
现在我们使用BERT的方式大多是微调,它有以下两个缺点:
1。 Finetune存在上下游阶段任务不一致的问题。fintune严重破坏了BERT原有的结构
2. 下游任务由注释数据驱动并微调到某个位置,但微调任务的语言意义并没有告知模型。当我们看待这两个缺点时,本质上是在精确微调和泛化能力强的MLM之间做出选择。
为了改善这两个不足,最重要的是让上下游任务阶段尽可能一致,这样才能发挥MLM的可能性。但这个过程中一定有人的因素,这是离散prompt的第一阶段:
第一步是建构prompt。
第二步是构建 MAKS 代币映射。
为此衍生出自动prompt、软prompt、连续prompt等方法。
下面详细说一下这两个缺点。
1。 Finetune存在上下游阶段任务不一致的问题。fintune严重破坏了BERT原有的结构
看第一点。学前阶段学习最重要的任务就是传销,那么我们是否也可以将传销用于下游应用呢? ?这是prompt的第一个想法。问题是如何让下游完成传销任务。
比如任务情绪分类,x = 我很累 y = 消极
第一步是构建prompt
然后我们可以这样添加prompt,prompt = 我感觉很♼ 然后我们可以得到给定BERT的token为
[CLS]我很累,感觉很[MASK][SEP],第二步是构造MAKS token映射
,即如何将MASK预测的token映射到标签上。例如,负面的可能的标记候选是:不愉快的、不好的、烦人的
这样我们就可以使上游和下游保持一致。
2。微调任务的语言意义并没有告知模型
我们知道BERT是一个语言模型,但是微调可以让他数据驱动的参数变化,而不是首先向他解释任务是什么。所以你会发现prompt使用的是流利语言,因为学前阶段的语料库也是流利语料库,所以我们构建prompt,希望句子X和prompt以流利的方式连接起来,这样上下游就可以了更加一致。
为了使拼写均匀,我们会根据场景来设计prompt。比如上面例子中使用的prompt感觉=非常[MASK]。当然也可以是放屁=气氛很【MASK】。
带着上述想法,prompt开始了阶段性的转变。第一阶段是离散的prompt,后来出现了连续的prompt。
01 第一阶段:谨慎prompt
模式挖掘训练
其实就是我们一开始讲的prompt方法,
第一步是构建prompt❝可以这样添加prompt,prompt=我感觉很[MASK]
所以给BERT的token可以得到为
[CLS]我很累,感觉很[MASK][SEP]第二步构建MAKS token映射
也就是MASK预测的token应该是怎样的映射到标签,例如否定的可能标记候选。就是:不愉快、不好、烦人
但这两个步骤都涉及人为因素。所以有的做了改进,自然侧重于如何去除人为设计,即“工程prompt”和“MAKS代币映射”。
其实在我看来,这就是prompt的优点,但是这个优点也带来了缺点,因为有人实验发现prompt的几句话就能导致模型效果发生很大的变化。
自动提示
为了消除手动设计带来的变量,autoprompt自动选择“MAKS token映射”并创建自动“prompt构建”的计划。
第一步是构建prompt
选择损失下降最大的prompt代币。请注意这里如何计算损失。在这一步中,我们首先需要提供掩码映射字。
这两个步骤其实是冲突的,先有鸡还是先有蛋。 。 。论文的方法是首先使用假prompt来喂它找到掩模映射,即:
[CLS] {sentence} [T] [T] [T] [MASK]. [SEP],然后使用获得的掩模映射来使用数据驱动的T选择。
第二步是构建MAKS token映射
第1步,使用上下文MASK token的输出嵌入作为x,并用标签训练逻辑。可以理解,logistic分数高的向量可以更好地表示标签
步骤2,利用contextMASK token的输出token的嵌入提供分数函数,得到分数top-k
有关许多详细信息,您可以阅读该论文。这种方法和微调的差距也相差了10个点。注意这里的罗伯塔大了,效果比垒BERT还要好。原因是大的传销能力更强。当我做MRC任务时,我也知道小和基之间的差距以及基和大之间的差距。模型参数数量越多,MLM能力越强。
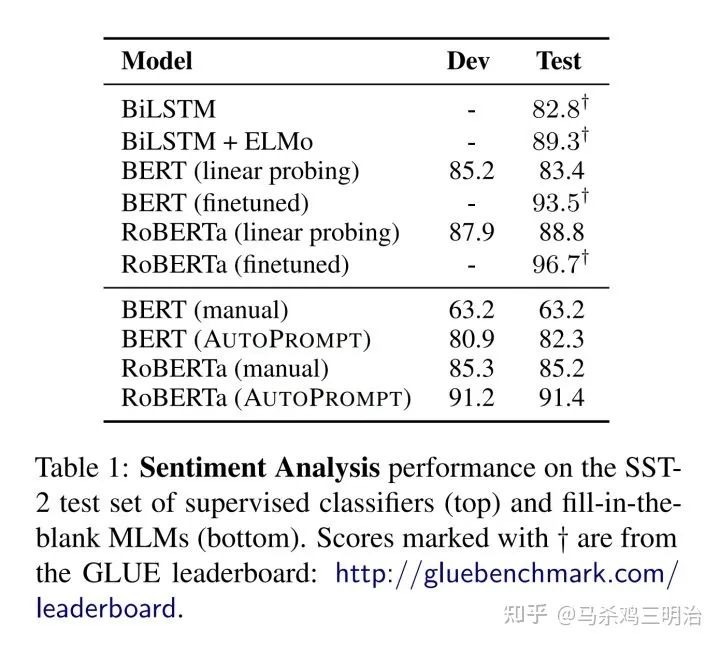
02 第二阶段:持续prompt
在这个阶段,prompt开始改变自己的品味。基本思想是用连续的prompt令牌替换以前离散的prompt令牌。如何改变它。
之前,prompt谨慎地喂伯特代币。例如,之前的情感分类给了 Bert prompt=“我感觉[MASK]”令牌。此后,prompt不断地用嵌入来代替这些符号。 ,将经过bert emebdding层的prompttoken的向量直接替换为可训练的参数,冻结整个BERT,只训练3*768的矩阵。例如,这里的token emebdding维度是3*768(我认为是三个单词),那么可训练参数是3*768,就是这样,你可以玩一些很酷的操作:
1,例如这里的3 *768,难道是20*768吗?这也是一个不可控的事情,可以尝试一下。
2。BERT的每个代码层可以加3*768吗?这意味着每一层的编码器通过自己的注意力将每一层的3*768信息交互到模型中。
3,不能用【MASK】贴图吗?我直接用CLS来分类。
上面提到的三点都是基于P-tuning v2的。至于P-tuning v2之前的玩法,我就不详细说了。技巧没有P-tuning v2那么多,但是P-tuning v2的效果是在大模型上。它接近于微调,您不需要训练太多参数来利用一些大型模型。 Prefix Tuning也表示,他们不需要训练太多的参数来利用一些大型模型,但这个游戏并不早。已经在那里了吗?现在这就是prompt旗下的水了,不是吗?
另外,在P-tuning v2中,prompt token的长度对实验影响很大,与任务有一定的相关性,性能很不稳定。论文没有进行几次实验,结果还有待确定。没有提及基础模型的效果。
其实看到这里你就会发现prompt变了。严格来说,他根本不是prompt。这种构建可训练向量来控制模型的方法并不罕见,并且 [MASK] 映射已被删除并由 CLS 代替进行分类。感觉更像fintune。由于我自己没有开过,所以看到负面评价居多。负面评论太多,无法在此列出。

03 第三步:收集上下游阶段的任务类型(T5、零prompt)
最后提到的是T5和零prompt。
T5是Google使用ender-decoder结构制作的大型模型。 T5 统一了 pretrain 阶段任务和下游阶段任务,都执行 seq2seq 任务,或者文章中提到的 text2text 任务。
零prompt将各种场景、各种任务类型(分类、翻译、阅读理解、近似句子评分等)的数据以人工设计的prompt的形式进行训练,实现超级无敌的prompt模型。事实上,本质上训练阶段之前的任务和步骤下游的任务是统一的,都是传销。不同的是,为了适应新的任务场景,零prompt需要一套算法来自动prompt,而T5则直接通过将任务类型与固定线索配对来解码答案。
两者相比,T5直接重新设计了pretrain阶段任务,与下游阶段任务保持一致,而零prompt本质上采用了自动prompt方法,只是贯穿所有中文任务数据,实现中文prompt统一。
04总结
prompt从原来的手工设计模板逐渐变形到自动prompt,再到连续prompt。
第一个人工设计模板是为了利用好BERT在预训练阶段学到的传销特性,然后在下游应用。但手动设计模型存在不稳定问题,自动prompt效果很差。
于是连续prompt开始行动了。连续的prompt已经不再有prompt的味道了。prompt变成了一个向量。通过训练,我们希望模型能够得到好的prompt向量。这其实就是微调。
所以不管prompt好不好,目前还不如微调。但他有一定的射击能力,尤其是谨慎的prompt。对于一些简单的任务,可以直接使用谨慎的prompt方法来实现少量的拍摄。这其实是利用了BERT在学前阶段学到的能力。但当任务难度太大时,几枪的效果就会很差,远不如标几条线。细化数据。这涉及到概括性和精确性。如果你想要一定程度的概括,你就必须牺牲精度。
最终,零prompt和T5几乎完成了prompt的所有事情。其实就是上下游是否一致的问题。 来源|知乎作者|马杀鸡三明治
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。






作者文章
- 用小程序学英语到底有没有用?适合哪些人?避坑指南加靠谱用法有吗? 2周前 (05-22)
- 2024-2025做通用和本地生活小程序没人看没人下单怎么办?试试这6个小成本留客转化型技巧 2周前 (05-22)
- 做小程序英文翻译避不开哪些坑?怎么翻才能吸引海外用户留存? 2周前 (05-21)
- Vue3 Composition API watch开启deep后踩过哪些坑?如何高效用它处理深层数据监听? 2周前 (05-19)
- Vue3中watch监听props时,deep:true到底该不该随便开? 2周前 (05-19)