 code前端网
code前端网AI工程师NLP入门实践:完整的机器处理流程
无论是刚入行AI行业的新人,还是想转行AI领域的技术工程师,都可以获取相关入门知识——本文中的NLP水平和实战。
有机器学习经验的人都知道,中文自然语言处理的过程与机器学习过程大致相同,但细节上有很多差异。我们来看看这9个不同的知识点:
1。 为什么要有分词?
我们知道,单词是自然语言处理中最小的处理单元。如果你的语料是句子、短文本和章节,我们要做的第一步就是分词。
因为英语的基本单位是单词,所以分词相对容易。 这句话基本上由标点符号、空格和单词组成,所以只需用空格和标点符号分隔单词即可。
首先是歧义问题。不同的分割方法导致不同的含义。目前中文分词基本分为两种:
- 基于词典的分词。 优点是简单有效,缺点是不能很好地解决单词歧义问题,尤其是在处理网络新流行单词时,性能很差。
- 基于统计的分词。 中文建模是通过人工标注完成的,然后对准备好的语料进行训练。通过计算不同阶段出现的概率,选择概率最大的情况作为分词的结果。这种分词方法虽然可以通过分词有效避免歧义,但对性能要求很高。
2。 Corpus
获取语料库,意思是语言材料。 语料库是语言学研究的内容。语料库是构成语料库的基本单位。所以,人们只是用文本作为替代,用文本中的上下文来替代现实世界中语言的上下文。
我们将文本集合称为语料库。如果有多个这样的文本集合,我们将其称为语料库集合(corpora)。 (定义来源:百度百科)根据语料来源,我们将语料分为以下两种类型:
1。现有语料库
许多业务部门、公司等组织收集了大量的纸质或电子文本材料。那么对于这些材料,如果条件允许的话,我们可以稍微整合一下,把所有的纸质文本数字化,作为语料库。
2。在线下载并采集语料库
如果您现在手头没有数据该怎么办?此时可以选择国内外标准开放数据集,如国内中文搜狗语料库和人民日报语料库。
国外大部分英语或外语暂时无法使用。你也可以选择通过爬虫爬取一些数据,然后继续后续的内容。
3。 语料预处理
这里重点关注语料预处理,在一个完整的中文自然语言处理技术应用中,语料处理大概会占到50%~70%的工作量,所以占开发人员总负荷的%大部分时间都花在语料库预处理上。
下面是通过数据清洗、分词、语音标注、去除停用词四大方面来完成语料库的预处理。
1。数据清洗
数据清洗,顾名思义,就是过滤语料库中有趣的东西,清理和去除被认为是噪音的不感兴趣的内容,包括从原文中提取标题、摘要、正文等信息。
抓取网站内容,去除广告、标签、HTML、JS等代码和评论。常见的数据清洗方法包括:手动去重、对齐、删除和标注等,或者通过规则提取内容、正则表达式匹配、基于词性和命名实体提取、编写脚本或代码批量处理等。
2.分词
中文语料数据是短文本或长文本的集合,例如句子、文章摘要、段落或整篇文章。一般来说,句子和段落之间的词和词是连续的,并且具有一定的含义。
在进行文本挖掘分析时,我们希望文本处理的最小单位粒度是词或者词,所以这时候就需要分词来对整个文本进行切分。
常见的分词算法有:基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词方法、基于规则的分词方法。每种方法都对应许多特定的算法。
当前中文分词算法的主要难点是歧义检测和新词检测。例如:“羽毛球拍卖结束”,这可以分为“羽毛球拍卖结束”,也可以分为“羽毛球拍卖结束”,如果不依赖于上下文的其他句子,很难知道如何理解它们。
3。词性标注
词性标注就是给每个单词或句子打上词性的标签,比如形容词、动词、名词等。后期处理。
例如联合文本分类不需要关心语音主题,但需要情感分析和知识推理。下图是一个常见的汉语词性排序。
![]() 常见的语音标注方法可以分为基于规则的方法和基于统计的方法。包括基于统计的方法,如基于最大熵的词性标注、统计最大概率输出词性和基于HMM的词性标注等。
常见的语音标注方法可以分为基于规则的方法和基于统计的方法。包括基于统计的方法,如基于最大熵的词性标注、统计最大概率输出词性和基于HMM的词性标注等。
4。删除停用词
停用词一般是指对文本特征没有贡献的单词,例如标点符号、情绪、人称等单词。因此,在一般的文本处理中,分词之后,下一步就是去除停用词。
4。 特征工程
完成语料预处理后,需要考虑分词成计算机可以计算的类型后,词与词如何表示。
当然,如果我们要计算的话,至少需要将中文分词字符串转换成数字。准确的说,应该是数学中的向量。常用的表示模型有两种:词袋模型和词向量。
Bag of Word (BOW)模型,不考虑句子中单词的原始顺序,立即将每个单词或符号放入一个集合(如列表)中,然后统计出现的次数。有时统计词频只是最基本的方法。 TF-IDF 是词袋模型的经典应用。
WordVektor 是一个将单词转换为单词和向量矩阵的计算模型。到目前为止,使用最广泛的单词表示方法是 one-hot,它将每个单词表示为一个长向量。
这个向量的维度就是词汇量大小,大部分元素都是0,只有一维值为1,代表当前单词。
还有 Google Team Word2Vec,主要包括两种模型:Skip-Gram 和 Continuous Bag of Words(CBOW),以及两种高效的训练方法:负采样(Negative Sampling)和分层 Softmax(Hierarchical Softmax) 。
值得一提的是,Word2Vec词向量可以更好地表达不同词之间的相似性和类比关系。此外,还有几种词向量表示,例如Doc2Vec、WordRank和FastText。
5。 特征选择
与数据挖掘一样,特征工程在文本挖掘相关问题中也至关重要。 在实际问题中,构造一个好的特征向量就是选择合适的、有表现力的特征。
文本特征大多是单词,具有语义信息。通过特征选择,可以找到仍能保留语义信息的特征子集;然而,特征提取找到的特征子空间会丢失部分语义信息。
所以特征选择是一个要求非常高的过程,更多地依赖经验和专业知识,并且特征选择有很多现成的算法。目前常见的特征选择方法有六种:DF、MI、IG、CHI、WLLR、WFO。
6。 模型训练
选择好特征向量后,接下来当然就是训练模型了。针对不同的应用需求,我们使用不同的模型,传统的有监督和无监督等机器学习模型。
如KNN、SVM、朴素贝叶斯、决策树、GBDT、K-means等模型; CNN、RNN、LSTM、Seq2Seq、FastText、TextCNN等深度学习模型这里。以下是训练模型时需要注意的一些要点。
1。关注过拟合和欠拟合问题,不断提高模型的泛化能力。
过拟合:模型的学习能力过强,也学习到了噪声数据的特征,导致模型的泛化能力下降。它在训练集上表现很好,但在测试集上表现很差。 。
常见的解决方案包括:
- 增加训练数据量;
- 添加正则化项,如L1正则化、L2正则化;
- 特征选择不合理,手动打开特征并使用特征选择算法;
- 使用dropout方法等。太容易了。
常见的解决方案包括:
- 添加其他功能项;
- 增加模型复杂度,例如在神经网络和线性模型中添加更多层,通过添加多项式使模型更具泛化性;
- 减少正则化参数。正则化的目的是避免过拟合,但现在模型欠拟合,就需要减少正则化参数。
2。对于神经网络,要注意梯度消失和梯度爆炸问题。
7。 评估指标
模型训练完成后,上线前必须对模型进行必要的评估,以便模型对语料库有更好的泛化能力。具体来说,可以提到以下指标。
1。错误率、精确度、准确度、精密度、召回率、F1 测量。
错误率:误分类样本数占样本总数的比例。对于样本集D,分类错误率计算如下:
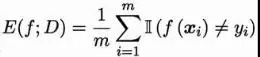
精度:正确分类的样本数占样本总数的比例。这里正确分类的样本数量不仅指正确分类的正例数量,还指正确分类的负例数量。对于样本集D,准确率计算公式如下:
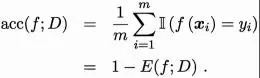
对于二分类问题,根据样本的组合,可以将样本分为真例(True Positive)和假正例(False Positive)他们的真实类别和学生的预测类别。 ,真阴性和假阴性。令TP、FP、TN、FN代表相应样本的数量。显然TP+FP++TN+FN=样本总数。 。分类结果的“混淆矩阵”如下:

准确率,缩写为P。准确率是针对我们的预测结果。它显示了预测的正样本中有多少是真正的正样本。定义公式如下:
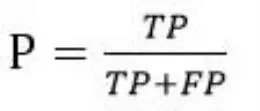
准确率,缩写为A。精度是正确分类的样本数与样本总数的比值。准确率反映了分类器对整个样本进行判断的能力(即能够将正数判断为正数,将负数判断为负数)。定义公式如下:
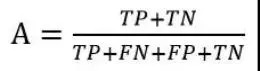
recall ,缩写为R。召回率是针对我们原始样本的。它显示了样本中有多少正例被正确预测。定义公式如下:
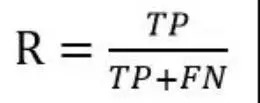
F1 衡量,表达对精确率/召回率的各种偏好。定义公式如下:
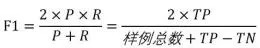
2.ROC曲线,AUC曲线。
ROC 代表“接收者操作特性”曲线。我们根据模型的预测结果将阈值从0更改为最大值,即每个样本最初被预测为正例。随着阈值的增加,学习器预测的正样本越来越少,直到最后没有样本是正样本。在这个过程中,每次计算两个重要量的值,并将它们绘制为横坐标和纵坐标,得到ROC曲线。
ROC曲线的纵轴是“真阳性率”(TPR),横轴是“假阳性率”(FPR)。两者分别定义为:
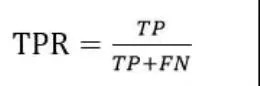
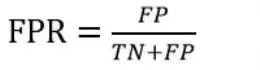
ROC曲线的意义有以下几点:
- ROC曲线可以很容易地认识到各个阈值对模型泛化性能的影响;
- 有助于选择最佳阈值;
- 可用于不同型号。对比表现,在同一坐标下,左上角的ROC曲线代表准确率最高的学生。
如果两条ROC曲线不相交,我们就可以确定哪条曲线最接近左上角,哪条曲线代表学生表现最好。然而,在实际任务中,情况却非常复杂。当两个模型的 ROC 曲线交叉时,很难普遍断定哪一个更好。如果这个时候一定要进行比较的话,比较合理的判断依据是比较ROC曲线下的面积,即AUC(Area Under ROC Curve)。
AUC 是 ROC 曲线下的面积,是衡量学生质量的表现指标。 AUC是衡量二分类模型好坏的评价指标,表示预测的正例先于负例被分类的概率。
之前我们讲的都是二分类问题,所以如果确实需要在多分类问题中使用ROC曲线,一般都会转化为多个“一对多”问题。即把其中一个作为正例,另一个作为反例,画出不同的ROC曲线。
8。 模特在线申请
模特在线申请,目前主流的申请方式是提供服务或者通过模特。
第一步是离线训练模型,然后在线部署模型并发布到接口服务以供业务系统使用。
第二种是在线培训。在线训练完成后,将模型pickle持久化,然后在线服务接口模板通过读取pickle来改变接口服务。
9。 模型重构(可选)
随着时间和变化,可能需要根据不同的业务优先级对模型进行一定程度的重构,包括上述的步骤一到步骤七。在线调整和重新训练模型。
文章出自苏永杰大师班《中文自然语言处理入门实战》,NLP是AI技术领域的一个重要分支。随着其技术范围不断扩大,在数据处理领域占据着越来越重要的地位。
版权声明
本文仅代表作者观点,不代表Code前端网立场。
本文系作者Code前端网发表,如需转载,请注明页面地址。





